21 KiB
21 KiB
Metadaten modellieren und Schnittstellen nutzen
- Austauschprotokolle für Metadaten (OAI-PMH, SRU)
- Metadaten über OAI-PMH harvesten mit VuFindHarvest
- XSLT Crosswalks mit MarcEdit
- Transformation von Metadaten mit OpenRefine
- Weitere Tools zur Metadatentransformation
- Nutzung von JSON-APIs
- Metadatenstandard LIDO
Zwischenstand (Schaubild):
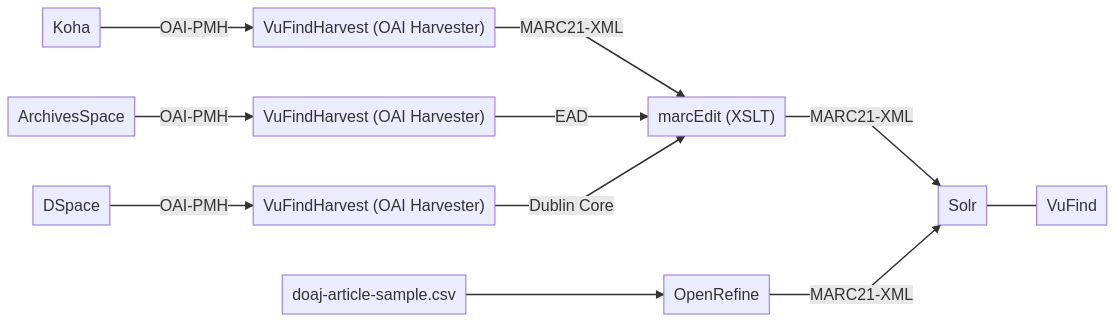
Note:
- Anders als in Lektion 1 geplant, nutzen wir als OAI Harvester VuFindHarvest statt metha. Das Schaubild wurde entsprechend aktualisiert.
- MarcEdit verfügt auch über eine Funktionalität, um OAI-PMH direkt zu harvesten. Zur besseren Illustration der Prozesse verwenden wir hier verschiedene Tools.
- Außerdem werden wir zusätzlich noch aus tabellarischen Beispieldaten (CSV) mit Hilfe der Software OpenRefine MARC21-XML modellieren.
Austauschprotokolle für Metadaten (OAI-PMH, SRU)
Es gibt zahlreiche Übertragungsprotokolle im Bibliotheks- und Archivbereich. Drei davon sind besonders weit verbreitet:
- Z39.50 (Library of Congress)
- SRU - Search/Retrieve via URL (Library of Congress)
- OAI-PMH - Open Archives Initiative Protocol for Metadata Harvesting (Open Archives Initiative)
Note:
- Z39.50 ist sehr alt, aber immer noch im Einsatz. Meist wird das modernere SRU als Ergänzung angeboten.
- Während Z39.50 und SRU sich besonders für Live-Abfragen oder gezielten Datenabruf mit vielen Parametern eignet, zielt OAI-PMH vor allem auf größere Datenabzüge und regelmäßige Aktualisierungen.
- Das Schöne an SRU und OAI-PMH ist, dass die Anfragen als Internetadresse (URL) zusammengestellt werden können und direkt über den Browser ohne Zusatzsoftware aufrufbar sind.
Metadaten über OAI-PMH harvesten mit VuFindHarvest
- Wir "ernten" (harvesten) die über die OAI-PMH-Schnittstellen angebotenen Daten
- Dazu verwenden wir das Tool VuFindHarvest, ein OAI Harvester aus dem VuFind-Projekt.
- Vorgehen:
- Sicherstellen, dass die OAI-PMH-Endpoints für Koha, ArchivesSpace und DSpace verfügbar sind
- Mit dem Tool die Daten abrufen und als XML auf der Festplatte speichern
Note:
- VuFind ist Solr-basiertes Discovery-System (wie Primo)
- VuFindHarvest ist OAI-Harvester (auch unabhängig von VuFind einsetzbar)
ArchivesSpace Fehlerkorrektur
- Wir haben beim Testen vorab festgestellt, dass die "Prudence Wayland Smith Papers" einen Erschließungsfehler beinhalten, der die Ausgabe als EAD über die OAI-PMH-Schnittstelle blockiert.
- Falls Sie diese EAD-Daten importiert hatten:
- Resource "Prudence Wayland-Smith Papers" aufrufen
- Im Bearbeitungsmodus nach
Language NoteAusschau halten. Darin ist fehlerhafter HTML-Code. - Diese Note löschen.
OAI-PMH Endpoints
- Koha sollte noch laufen
- http://bibliothek.meine-schule.org/cgi-bin/koha/oai.pl
- Format:
marcxml
- ArchivesSpace muss ggf. gestartet werden
- http://localhost:8082 (Meldung
Parameter required but no value providedist OK) - Format:
oai_ead
- http://localhost:8082 (Meldung
- DSpace Demo wird jede Samstag Nacht gelöscht
- http://demo.dspace.org/oai/request
- Format:
oai_dc - Set:
com_10673_1(Sample Community)
VuFindHarvest 4.0.1 installieren
- Die Software wird bei GitHub veröffentlicht: https://github.com/vufind-org/vufindharvest
- Sie ist in PHP geschrieben. Für die Installation wird composer (Paketverwaltung für PHP) empfohlen.
sudo apt update
sudo apt install composer php php-xml
cd ~
wget https://github.com/vufind-org/vufindharvest/archive/v4.0.1.zip
unzip v4.0.1.zip
cd vufindharvest-4.0.1
composer install
Übung: Harvesting
Gruppenarbeit (20 Minuten)
- Laden Sie mit VuFindHarvest die Daten aus
- a) Koha http://bibliothek.meine-schule.org/cgi-bin/koha/oai.pl im Format
marcxml - b) ArchivesSpace http://localhost:8082 im Format
oai_ead - c) DSpace http://demo.dspace.org/oai/request das Set
com_10673_1im Formatoai_dc
- a) Koha http://bibliothek.meine-schule.org/cgi-bin/koha/oai.pl im Format
- Hinweise:
- Benutzungshinweise in der README.md
- Speichern Sie die Daten in verschiedenen Ordnern.
- Beispiel:
cd ~/vufindharvest-4.0.1
php bin/harvest_oai.php --url=http://example.com/oai_server --metadataPrefix=oai_dc my_target_dir
XSLT Crosswalks mit MarcEdit
- Wir haben in der vorigen Übung Daten in verschiedenen Formaten (MARC21-XML, EAD und DC) geladen.
- Nun werden wir diese einheitlich in MARC21-XML konvertieren.
Crosswalks? XSLT?
- Crosswalks
- Gängiger Begriff, um die Konvertierung von einem Metadatenstandard in einen anderen zu beschreiben.
- Beispiel: MARC21 zu Dublin Core.
- Der "Crosswalk" beinhaltet Regeln wie Elemente und Werte zugeordnet/verändert werden müssen (sog. Mapping).
- Im Idealfall verlustfrei, aber meist keine 1:1-Zuordnung möglich.
- XSLT
- Programmiersprache zur Transformation von XML-Dokumenten (W3C Empfehlung, 1999)
- Literaturempfehlung für Einstieg in XSLT: https://programminghistorian.org/en/lessons/transforming-xml-with-xsl
MarcEdit 7 installieren
- MarcEdit ist eine kostenlos nutzbare Software aber nicht Open Source (siehe Lizenz)
- Sie ist die meistgenutzte Zusatzsoftware für die Arbeit mit MARC21.
- Offizielle Webseite: https://marcedit.reeset.net
- Installation von Mono (MarcEdit ist in .NET geschrieben und benötigt unter Linux diese Laufzeitumgebung) und des Unicode Fonts "Noto":
sudo apt install mono-complete fonts-noto
- Installation von MarcEdit:
cd ~
wget https://marcedit.reeset.net/software/marcedit7/marcedit7.run
chmod +x marcedit7.run
mkdir ~/marcedit
./marcedit7.run --target ~/marcedit
MarcEdit konfigurieren
- Der Installer hat das Programm MarcEdit im Startmenü (unten links) registriert. Starten Sie darüber das Programm.
- Achtung: Die Voreinstellungen in der Linux-Version von MarcEdit sind fehlerhaft. Sie können wie folgt korrigiert werden:
- MARC Tools
- Button Tools / Edit XML Function List
- Für alle benötigten Funktionen:
- Im Menü "Defined Functions" die gewünschte Funktion auswählen und Modify klicken
- Unter XSLT/XQuery Path
XSLT\durchxslt/ersetzen - Anschließend "Save" und für nächste Funktion wiederholen
XSLT Crosswalks anwenden
Aufgabe (20 Minuten)
- Konvertieren Sie einige Daten aus ArchivesSpace (EAD) und aus DSpace (DC) nach MARC21XML. Speichern Sie die Daten auf der Festplatte.
- Prüfen Sie grob, ob die konvertierten Daten korrekt aussehen.
- Anleitung für "XML Conversion" mit MarcEdit von der Unibibliothek aus Illinois: https://guides.library.illinois.edu/c.php?g=463460&p=3168159
Note:
- Von MarcEdit verwendete XSLT Dateien liegen auch hier: https://github.com/reeset/marcedit_xslt_files und https://github.com/reeset/marcedit-xslts
Zur Vertiefung
Optionale Aufgabe (2 Stunden)
- Bearbeiten Sie die Lehrmaterialien von Library Carpentry zu MarcEdit
Transformation von Metadaten mit OpenRefine
Installation OpenRefine 3.4.1
- Auf der Seite Download das "Linux kit" herunterladen
cd ~ wget https://github.com/OpenRefine/OpenRefine/releases/download/3.4.1/openrefine-linux-3.4.1.tar.gz - Das Tar-Archiv entpacken
tar -xzf openrefine-linux-3.4.1.tar.gz - In den entpackten Ordner wechseln und dort im Terminal den Befehl "./refine" aufrufen
cd ~/openrefine-3.4.1 ./refine - Nach ca. 15 Sekunden sollte sich der Browser öffnen. Falls nicht, manuell Firefox starten und http://localhost:3333 eingeben.
Note:
- OpenRefine benötigt JAVA. Das haben wir schon auf unserer virtuellen Maschine, weil wir es für ArchivesSpace installiert hatten.
./ist unter Linux eine Abkürzung für "in diesem Verzeichnis". Einfach nurrefinereicht hier nicht aus, weil das Terminal dann nicht sicher weiß, ob Sie einen systemweit installierten Befehlrefineoder die Dateirefineim aktuellen Verzeichnis meinen. Daher muss zum Ausführen von Dateien im selben Verzeichnis das./vorangestellt werden.
Einführung in OpenRefine
- Claim
- Einsatzbereiche
- Anwender*innen
- Formate
- Einsatzmöglichkeiten
- Historie
Claim von OpenRefine
"A free, open source, powerful tool for working with messy data"
- grafische Oberfläche, die einer klassischen Tabellenverarbeitungssoftware ähnelt
- dient der Analyse, Bereinigung, Konvertierung und Anreicherung von Daten
- wird in der Regel lokal auf einem Computer installiert und über den Browser bedient
Einsatzbereiche

Note:
- Aus Umfrage vom OpenRefine-Team, n = 178
Anwender*innen

Von OpenRefine unterstützte Formate
- Besonders geeignet für tabellarische Daten (CSV, TSV, XLS, XLSX und auch TXT mit Trennzeichen oder festen Spaltenbreiten)
- Einfaches "flaches" XML (z.B. MARCXML) oder JSON ist mit etwas Übung noch relativ einfach zu modellieren
- Komplexes XML mit Hierarchien (z.B. EAD) ist möglich, aber nur mit Zusatztools
- Kann auch in Kombination mit MarcEdit für Analyse und Transformation von MARC21 benutzt werden
Einsatzmöglichkeiten von OpenRefine
- Exploration von Datenlieferungen
- Vereinheitlichung und Bereinigung (zur Datenqualität in der Praxis siehe Präsentation von Peter Király "Validating 126 million MARC records")
- Abgleich mit Normdaten ("Reconciliation") in Wikidata, GND und VIAF
- Für lokalen Einsatz ausgelegt (Installation auf Webservern und Automatisierung möglich, aber nur mit Zusatzsoftware)
Historie
https://github.com/OpenRefine/OpenRefine/graphs/contributors
Note:
- 2010-05: Freebase Gridworks
- 2011-12-11: Google Refine 2.5
- 2015-04-30: OpenRefine 2.6 rc1
- 2017-06-18: OpenRefine 2.7
- 2020-09-06: OpenRefine 3.4
Übung Library Carpentry Lesson
Aufgabe (4 Stunden)
- Bearbeiten Sie die Lehrmaterialien von Library Carpentry zu OpenRefine
Übung: CSV nach MARCXML mit OpenRefine
- Wir nutzen die Funktion Templating Exporter. Diese findet sich oben rechts im Menü Export > Templating
- Beschreibung des MARC21 Formats für bibliografische Daten mit Liste der Felder: https://www.loc.gov/marc/bibliographic/
- Beispieldatei der Library of Congress für MARC21 mit mehreren Dokumenten: https://www.loc.gov/standards/marcxml/xml/collection.xml
Note:
- Das Vorgehen ist ähnlich wie bei XSLT Crosswalks, nur dass das "Template" hier direkt bearbeitet werden kann und nicht bereits fest steht, wie bei MarcEdit.
- OpenRefine verwendet eine eigene Template-Sprache (GREL) statt XSLT.
Voraussetzung für die Übung
- OpenRefine (lokal oder auf dem Server)
- Ein Projekt mit den Beispieldaten aus der Library Carpentry Lesson.
- Schnell neu zu erstellen mit: Create > Web Addresses (URL)
https://raw.githubusercontent.com/LibraryCarpentry/lc-open-refine/gh-pages/data/doaj-article-sample.csv
Vorlage als Ausgangsbasis
-
Prefix:
<collection xmlns="http://www.loc.gov/MARC21/slim"> -
Row Separator: (Zeilenumbruch)
-
Suffix:
</collection> -
Row Template:
<record> <leader> nab a22 uu 4500</leader> <controlfield tag="001">{{cells['URL'].value.replace('https://doaj.org/article/','').escape('xml')}}</controlfield> <datafield tag="022" ind1=" " ind2=" "> <subfield code="a">{{cells['ISSNs'].value.escape('xml')}}</subfield> </datafield> <datafield tag="100" ind1="0" ind2=" "> <subfield code="a">{{cells['Authors'].value.split('|')[0].escape('xml')}}</subfield> </datafield> <datafield tag="245" ind1="0" ind2="0"> <subfield code="a">{{cells["Title"].value.escape('xml')}}</subfield> </datafield>{{ forEach(cells['Authors'].value.split('|').slice(1), v ,' <datafield tag="700" ind1="0" ind2=" "> <subfield code="a">' + v.escape('xml') + '</subfield> </datafield>') }} </record>
Aufgabe 1: "Reverse Engineering"
- Beschreiben Sie anhand des Vergleichs der Ausgangsdaten mit dem Ergebnis mit ihren eigenen Worten welche Transformationen für die jeweiligen Felder durchgeführt wurden.
- Versuchen Sie die Aufgabe in der Gruppenarbeit zunächst einzeln zu lösen (10 min) und diskutieren Sie dann in der Gruppe.
- Dokumentieren Sie abschließend bitte hier das Gruppenergebnis.
Aufgabe 2: Template ergänzen
- Suchen Sie für weitere Spalten in den DOAJ-Daten die Entsprechung in MARC21: https://www.loc.gov/marc/bibliographic/
- Erstellen Sie geeignete Regeln im Template, um die Daten der gewählten Spalten in MARC21 zu transformieren.
- Dokumentieren Sie das gewählte MARC21-Feld und den zugehörigen Abschnitt aus dem Template.
Hinweise zur Vervollständigung
Wenn die Spalten leere Zellen enthalten, dann Funktion forNonBlank() nutzen. Beispiel:
{{
forNonBlank(
cells['DOI'].value,
v,
'<datafield tag="024" ind1="7" ind2=" ">
<subfield code="a">' + v.escape('xml') + '</subfield>
<subfield code="2">doi</subfield>
</datafield>',
''
)
}}
Exkurs: XML-Deklaration
- Um verarbeitenden Programmen mitzuteilen, dass es sich bei einer (Text-)Datei um XML handelt, wird dies üblicherweise am Anfang der Datei "deklariert":
<?xml version="1.0" encoding="utf-8" standalone="yes"?>- Es handelt sich um eine XML-Datei
- Sie entspricht dem XML-Standard in Version 1.0
- Die Zeichenkodierung erfolgt im Standard Unicode
- Die Datei enthält eine Dokumenttypdefinition (DTD)
- Nur
versionist eine Pflichtangabe,encoding-Angaben gehören aber zur guten Praxis - Die Reihenfolge der Attribute ist festgelegt!
Validieren mit xmllint
- Wir exportieren das Gesamtergebnis als XML in ein neues Verzeichnis.
- Für die Validierung können Sie das Programm
xmllintverwenden, das unter Ubuntu vorinstalliert ist. - Zum Abgleich gegen das offizielle Schema von MARC21 laden wir dieses (XSD) zunächst herunter.
wget https://www.loc.gov/standards/marcxml/schema/MARC21slim.xsd
xmllint *.xml --noout --schema MARC21slim.xsd
Weitere Tools zur Metadatentransformation
- Motivation
- Vergleich mit anderen Tools
Zur Motivation
Metadaten-Management in der Praxis, hier beim Leibniz-Informationszentrum Wirtschaft (ZBW) in Hamburg:
- Infoseite: https://www.zbw.eu/de/ueber-uns/arbeitsschwerpunkte/metadaten/
- Videointerview mit Kirsten Jeude: https://www.youtube.com/watch?v=YwbRTDvt_sA
Vergleich mit anderen Tools
- Merkmale von OpenRefine:
- grafische Oberfläche: Transformationsergebnisse werden direkt sichtbar
- Skriptsprachen (GREL, Jython, Clojure) für komplexe Transformationen
- Schwerpunkt auf Datenanreicherung (Reconciliation)
- Alternative Software:
- Catmandu (Perl)
- Metafacture (Java)
- MarcEdit (für MARC21)
- Siehe auch: Prof. Magnus Pfeffer (2016): Open Source Software zur Verarbeitung und Analyse von Metadaten. Präsentation auf dem 6. Bibliothekskongress. http://nbn-resolving.de/urn/resolver.pl?urn:nbn:de:0290-opus4-24490
Note:
- Generell gilt, dass die passende Software anhand des Anwendungsfalls gewählt werden sollte.
- In der Praxis wird oft die Software verwendet, die schon gut beherrscht wird. Das macht es manchmal sehr umständlich.
- Wer eine generische Programmiersprache wie Python gut beherrscht, kommt auch damit zum Ziel. Für Python gibt es übrigens eine Library für MARC21: https://pymarc.readthedocs.io
Nutzung von JSON-APIs
- Moderne APIs liefern oft Antworten im Format JSON (statt XML wie bei SRU oder OAI-PMH)
- JSON lässt sich ebenso wie XML im Browser anschauen und gut maschinell verarbeiten
Beispiel für API: lobid-gnd
- Suchergebnisse als JSON
- Datensätze über ID direkt als JSON abrufen
- Bulk-Downloads mit JSON lines
- Was kann man damit bauen? Beispiel Autovervollständigung
Beispiel für Tool: scrAPIr
- Das Tool erlaubt Daten von bekannten Webseiten zu beziehen
- genutzt werden dazu die APIs der Webseiten (in der Regel JSON)
- es werden auch Vorlagen für Code (Javascript, Python) bereitgestellt
- Beispiel Google Books: https://scrapir.org/data-management?api=Google_Books
Reconciliation API
- In W3C Community Group Entity Reconciliation entwickelter Entwurf für einen Standard: Reconciliation Service API, v0.1, 20.8.2020
- Übersicht vorhandener Schnittstellen: https://reconciliation-api.github.io/testbench/
- Nur ein kleiner Teil (u.a. Wikidata und lobid-gnd) unterstützt die Funktionen "Suggest" und "Extend Data"
- Für Wikidata pflegt das OpenRefine-Team die Schnittstelle. Hier gab es leider in letzter Zeit einen Wechsel der URL und Performance-Probleme.
Metadatenstandard LIDO
- Lightweight Information Describing Objects ist ein auf dem CIDOC Conceptual Reference Model (CRM) basierender XML-Standard zur Beschreibung von Kulturobjekten
- CIDOC CRM definiert URI für Konzepte und Relationen
- LIDO verwendet eine an CIDOC CRM orientierte Terminologie
- LIDO folgt dem Linked Open Data-Paradigma
- besonderes Merkmal von LIDO ist die ereignis-zentrierte Beschreibung von Objekten (Ereignisse als Entitäten)
- durch die spezielle Struktur ist die verlustfreie Transformation in andere Formate jedoch schwierig
LIDO - Struktur
- deskriptive Metadaten:
- Identifikation (Titel/Name, Beschreibung, Maße, etc.)
- Klassifikation (Art, Gattung, Form, etc.)
- Ereignisse (Herstellung, Bearbeitung, Besitzwechsel, Restaurierung, etc.)
- Relationen (Objekte, Personen, Orte, etc.)
- administrative Metadaten:
- Rechte (Objekt, Datensatz, Nutzung, Verbreitung, etc.)
- Datensatz (Identifikation, Urheber, etc.)
- Ressourcen (Digitalisat, Nachweis, etc.)
- Unterscheidung zwischen display elements und index elements
LIDO - Einordnung
- Auch LIDO ist letztlich "nur" ein XML-Format, kann also mit denselben Werkzeugen und Methoden verarbeitet werden, die Sie in den vergangenen Lehreinheiten bereits im Umgang mit anderen Formaten kennengelernt haben
- Das spezielle Konzept von LIDO macht das Format nicht wesentlich komplizierter als andere Formate, es ist lediglich im Vergleich ungewohnt
LIDO - Crosswalks
- Zur Orientierung sind vielleicht die Transformationsregeln der Deutschen Digitalen Bibliothek (DDB) und der Europeana interessant
- DDB
- Excel-Datei mit Mappings (v1.9)
- Erklärende Präsentationsfolien (v1.4)
- Europeana (EDM)
- Beschreibung mit Beispiel (S. 43ff.)
- DDB
- Broschüre Implementing LIDO aus dem EU-Projekt AthenaPlus von 2015
- Auf der Konferenz ELAG gab es 2018 einen Vortrag zur Aggregation von LIDO-XML Daten in einen "DataHub":
- Matthias Vandermaesen: The Datahub Project: De/blending Museum Data
- Catmandu beinhaltet ein Modul für LIDO
Aufgaben
Bis zum nächsten Termin:
- Beitrag im Lerntagebuch zu dieser Lehreinheit
- Aufgabe Anreicherung mit lobid-gnd
- Reichern Sie die Autorennamen in den DOAJ-Daten um zusätzliche Informationen (z.B. GND-Nummer und Geburtsjahr) aus lobid-gnd an.
- Erweitern Sie das Template und exportieren Sie die Daten in XML.
- Hinweis: Im MARC21 Format gehören weiterführende Informationen zu Autoren in Unterfelder der Felder 100 und 700. Siehe Beispiele in der Formatdokumentation
- Berichten Sie über diese Aufgabe in einem extra Artikel in Ihrem Lerntagebuch.