31 KiB
Metadaten modellieren und Schnittstellen nutzen
- Zwischenstand (Schaubild)
- Auswertung der Übung zu DSpace
- Austauschprotokolle für Metadaten (OAI-PMH, SRU)
- Metadaten über OAI-PMH harvesten mit VuFindHarvest
- XSLT Crosswalks mit MarcEdit
- Transformation von Metadaten mit OpenRefine
- Weitere Tools zur Metadatentransformation
- Nutzung von JSON-APIs
Zwischenstand (Schaubild)
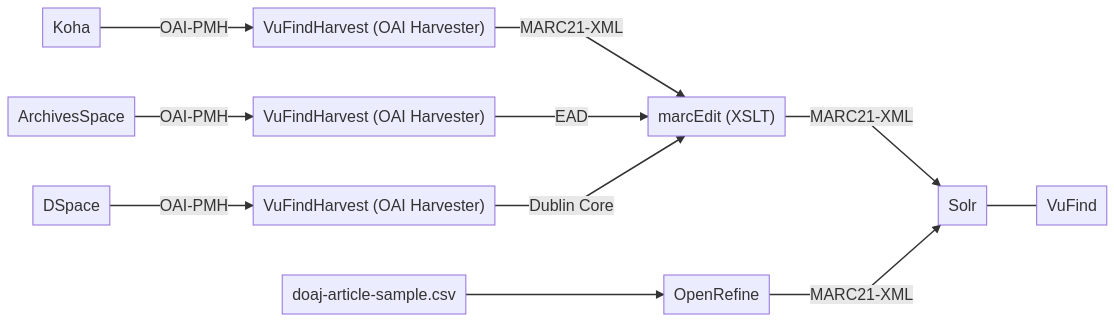
Note:
- Wir haben die Demo von DSpace getestet und in der Übung Daten aus DSpace über die OAI-PMH-Schnittstelle abgerufen.
- Nun wollen wir auch die OAI-PMH-Schnittstellen von unseren lokal installierten Systemen Koha und ArchivesSpace abrufen.
- Anschließend bearbeiten wir die Daten mit marcEdit.
- Danach schauen wir uns dann noch die Software OpenRefine an und verwenden dazu weitere Beispieldaten.
Auswertung der Übung zu DSpace
- Aufgabe war, von Ihnen erstellte Daten in der DSpace-Demo über die OAI-PMH-Schnittstelle abzurufen und auf der virtuellen Maschine zu speichern.
- Falls das nicht geklappt hat, finden Sie hier Beispieldaten: https://pad.gwdg.de/caRGeiZbTD2AyEa7VMVEug
- Achtung! Wenn Sie Ihre eigenen Daten aus DSpace verwenden wollen, müssen Sie bitte die erste Zeile durch Folgendes ersetzen:
<oai_dc:dc xmlns:oai_dc="http://www.openarchives.org/OAI/2.0/oai_dc/" xmlns:doc="http://www.lyncode.com/xoai" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:dc="http://purl.org/dc/elements/1.1/" xsi:schemaLocation="http://www.openarchives.org/OAI/2.0/oai_dc/ http://www.openarchives.org/OAI/2.0/oai_dc.xsd"> - Ursache: Bei den von Hand aus der OAI-Schnittstelle kopierten Daten fehlen Namespace-Deklarationen. Das würde zu einem Absturz von MarcEdit führen.
Austauschprotokolle für Metadaten (OAI-PMH, SRU)
Es gibt zahlreiche Übertragungsprotokolle im Bibliotheks- und Archivbereich. Drei davon sind besonders weit verbreitet:
- Z39.50 (Library of Congress)
- SRU - Search/Retrieve via URL (Library of Congress)
- OAI-PMH - Open Archives Initiative Protocol for Metadata Harvesting (Open Archives Initiative)
Note:
- Z39.50 ist sehr alt, aber immer noch im Einsatz. Meist wird das modernere SRU als Ergänzung angeboten.
- Während Z39.50 und SRU sich besonders für Live-Abfragen oder gezielten Datenabruf mit vielen Parametern eignet, zielt OAI-PMH vor allem auf größere Datenabzüge und regelmäßige Aktualisierungen.
- Das Schöne an SRU und OAI-PMH ist, dass die Anfragen als Internetadresse (URL) zusammengestellt werden können und direkt über den Browser ohne Zusatzsoftware aufrufbar sind.
Metadaten über OAI-PMH harvesten mit VuFindHarvest
- Wir "ernten" (harvesten) die über die OAI-PMH-Schnittstellen angebotenen Daten.
- Dazu verwenden wir das Tool VuFindHarvest, ein OAI Harvester aus dem VuFind-Projekt.
- Vorgehen:
- Sicherstellen, dass die OAI-PMH-Endpoints für Koha und ArchivesSpace verfügbar sind
- Mit dem Tool die Daten abrufen und als XML auf der Festplatte speichern
Note:
- VuFind ist ein auf der Suchmaschine Apache Solr basierendes Discovery-System (wie Primo)
- VuFindHarvest ist OAI-Harvester (auch unabhängig von VuFind einsetzbar)
OAI-PMH Endpoints
- Koha sollte noch laufen
- http://bibliothek.meine-schule.org/cgi-bin/koha/oai.pl
- Meldung
No verb suppliedist OK - Format:
marcxml
- ArchivesSpace muss ggf. gestartet werden
- http://localhost:8082
- Meldung
Parameter required but no value providedist OK - Format:
oai_ead
VuFindHarvest 4.1.0 installieren
- Die Software wird bei GitHub veröffentlicht: https://github.com/vufind-org/vufindharvest
- Sie ist in PHP geschrieben. Für die Installation wird composer (Paketverwaltung für PHP) empfohlen.
sudo apt update
sudo apt install composer php php-xml
cd ~
wget https://github.com/vufind-org/vufindharvest/archive/v4.1.0.zip
unzip v4.1.0.zip
cd vufindharvest-4.1.0
composer install
Übung: Harvesting
Aufgabe (20 Minuten)
- Laden Sie mit VuFindHarvest die Daten aus
- a) Koha http://bibliothek.meine-schule.org/cgi-bin/koha/oai.pl im Format
marcxml - b) ArchivesSpace http://localhost:8082 im Format
oai_ead
- a) Koha http://bibliothek.meine-schule.org/cgi-bin/koha/oai.pl im Format
- Hinweise:
- Benutzungshinweise in der README.md
- Speichern Sie die Daten in verschiedenen Ordnern.
- Beispiel (muss abgewandelt werden):
cd ~/vufindharvest-4.1.0
php bin/harvest_oai.php --url=http://example.com/oai_server --metadataPrefix=oai_dc my_target_dir
Beispieldaten
- Falls Sie die Übung zu DSpace nicht abschließen konnten oder das Harvesting von Koha und ArchivesSpace nicht geklappt hat, können Sie die Beispieldaten verwenden.
- Dokument mit den gesammelten Beispieldaten: https://pad.gwdg.de/caRGeiZbTD2AyEa7VMVEug
- Markieren Sie die XML-Daten, kopieren Sie diese in einen Text Editor auf der virtuellen Maschine und speichern Sie die Datei an einer beliebigen Stelle ab.
XSLT Crosswalks mit MarcEdit
- Wir haben nun Daten in verschiedenen Formaten (MARC21-XML, EAD und DC) vorliegen.
- Nun werden wir diese einheitlich in MARC21-XML konvertieren.
Crosswalks? XSLT?
- Crosswalks
- Gängiger Begriff, um die Konvertierung von einem Metadatenstandard in einen anderen zu beschreiben.
- Beispiel: Dublin Core zu MARC21.
- Der "Crosswalk" beinhaltet Regeln wie Elemente und Werte zugeordnet werden (sog. Mapping).
- Im Idealfall verlustfrei, aber meist keine 1:1-Zuordnung möglich.
- XSLT
- Programmiersprache zur Transformation von XML-Dokumenten (W3C Empfehlung, 1999)
- Literaturempfehlung für Einstieg in XSLT: https://programminghistorian.org/en/lessons/transforming-xml-with-xsl
MarcEdit 7 installieren
- MarcEdit ist eine kostenlos nutzbare Software aber nicht Open Source (siehe Lizenz)
- Sie ist die meistgenutzte Zusatzsoftware für die Arbeit mit MARC21.
- Offizielle Webseite: https://marcedit.reeset.net
- Installation von Mono (MarcEdit ist in .NET geschrieben und benötigt unter Linux diese Laufzeitumgebung) und des Unicode Fonts "Noto":
sudo apt install mono-complete fonts-noto - Installation von MarcEdit:
cd ~ wget https://marcedit.reeset.net/software/marcedit7/marcedit7.run chmod +x marcedit7.run mkdir ~/marcedit ./marcedit7.run --target ~/marcedit
MarcEdit konfigurieren
- Der Installer hat das Programm MarcEdit im Startmenü (unten links) registriert. Starten Sie darüber das Programm.
- Achtung: Die Voreinstellungen in der Linux-Version von MarcEdit sind fehlerhaft. Sie können wie folgt korrigiert werden:
- MARC Tools
- Button Tools / Edit XML Function List
- Für die benötigten Funktionen (EAD=>MARC und OAIDC=>MARCXML):
- Im Menü "Defined Functions" die gewünschte Funktion auswählen und Modify klicken
- Unter XSLT/XQuery Path
XSLT\durchxslt/ersetzen - Anschließend "Save" und für nächste Funktion wiederholen
XSLT Crosswalks anwenden
Aufgabe (20 Minuten)
- Konvertieren Sie einige Daten aus ArchivesSpace (EAD) und aus DSpace (OAIDC) nach MARC21XML. Speichern Sie die Daten auf der Festplatte.
- Im Auswahldialog für die zu konvertierenden Dateien achten Sie bitte darauf, dass der Filter auf "All Files (*.*)" gesetzt ist.
- Es gibt keine direkte Transformation von EAD zu MARC21XML, Sie benötigen also zwei Schritte:
- EAD -> MARC
- MARC21 -> MARC21XML
- Prüfen Sie grob, ob die konvertierten Daten korrekt aussehen.
- Anleitung für "XML Conversion" mit MarcEdit von der Unibibliothek aus Illinois: https://guides.library.illinois.edu/c.php?g=463460&p=3168159
Note:
- Von MarcEdit verwendete XSLT Dateien liegen auch hier: https://github.com/reeset/marcedit_xslt_files und https://github.com/reeset/marcedit-xslts
Zur Vertiefung
Optionale Aufgabe (2 Stunden)
- Bearbeiten Sie die Lehrmaterialien von Library Carpentry zu MarcEdit
Transformation von Metadaten mit OpenRefine
Einführung in OpenRefine
- Claim
- Einsatzbereiche
- Anwender*innen
- Formate
- Einsatzmöglichkeiten
- Historie
Claim von OpenRefine
"A free, open source, powerful tool for working with messy data"
- grafische Oberfläche, die einer klassischen Tabellenverarbeitungssoftware ähnelt
- dient der Analyse, Bereinigung, Konvertierung und Anreicherung von Daten
- wird in der Regel lokal auf einem Computer installiert und über den Browser bedient
Einsatzbereiche

Note:
- Aus Umfrage vom OpenRefine-Team, n = 178
Anwender*innen

Von OpenRefine unterstützte Formate
- Besonders geeignet für tabellarische Daten (CSV, TSV, XLS, XLSX und auch TXT mit Trennzeichen oder festen Spaltenbreiten)
- Einfaches "flaches" XML (z.B. MARCXML) oder JSON ist mit etwas Übung noch relativ einfach zu modellieren
- Komplexes XML mit Hierarchien (z.B. EAD) ist möglich, aber nur mit Zusatztools
- Kann auch in Kombination mit MarcEdit für Analyse und Transformation von MARC21 benutzt werden
Einsatzmöglichkeiten von OpenRefine
- Exploration von Datenlieferungen
- Vereinheitlichung und Bereinigung (zur Datenqualität in der Praxis siehe Präsentation von Peter Király "Validating 126 million MARC records")
- Abgleich mit Normdaten ("Reconciliation") in Wikidata, GND und VIAF
- Für lokalen Einsatz ausgelegt (Installation auf Webservern und Automatisierung möglich, aber nur mit Zusatzsoftware)
Historie
https://github.com/OpenRefine/OpenRefine/graphs/contributors
Note:
- 2010-05: Freebase Gridworks
- 2011-12-11: Google Refine 2.5
- 2015-04-30: OpenRefine 2.6 rc1
- 2017-06-18: OpenRefine 2.7
- 2020-09-06: OpenRefine 3.4
- 2021-11-07: OpenRefine 3.5.0
Installation OpenRefine 3.5.0
- Die OpenRefine-Version für Linux herunterladen
cd ~ wget https://github.com/OpenRefine/OpenRefine/releases/download/3.5.0/openrefine-linux-3.5.0.tar.gz - Das Tar-Archiv entpacken
tar -xzf openrefine-linux-3.5.0.tar.gz - In den entpackten Ordner wechseln und dort im Terminal den Befehl "./refine" aufrufen
cd ~/openrefine-3.5.0 ./refine - Im Firefox-Browser auf der virtuellen Maschine die Adresse http://localhost:3333 aufrufen.
Note:
- OpenRefine benötigt JAVA. Das haben wir schon auf unserer virtuellen Maschine, weil wir es für ArchivesSpace installiert hatten.
./ist unter Linux eine Abkürzung für "in diesem Verzeichnis". Einfach nurrefinereicht hier nicht aus, weil das Terminal dann nicht sicher weiß, ob Sie einen systemweit installierten Befehlrefineoder die Dateirefineim aktuellen Verzeichnis meinen. Daher muss zum Ausführen von Dateien im selben Verzeichnis das./vorangestellt werden.
Übung Library Carpentry Lesson
- In den vorigen Semestern haben wir das Kennenlernen von OpenRefine als Hausaufgabe aufgegeben. Das ist wegen dem Ersatztermin diesmal nicht möglich.
- Wir gehen deshalb nun ein paar Basisfunktionen gemeinsam durch, damit Sie einen Eindruck von der Software erhalten.
- Bei Interesse können Sie die Lehrmaterialien von Library Carpentry zu OpenRefine (ca. 4 Stunden) zur Vertiefung durchgehen.
- Anschließend nutzen wir OpenRefine, um weitere Daten in MARCXML zu konvertieren.
Beispieldaten laden
- Create Project > Web Addresses (URL)
- Automatisch erkannte Einstellungen für den Import können so belassen werden.
- Mit Button
Create Projectoben rechts den Import starten.
Vorführung von Basisfunktionen
- Spalte Language > Facet > Text Facet
- Spalte Authors > Edit cells > Split multi-valued cells... > Separator: |
- Spalte Authors > Edit cells > Cluster and edit...
- Spalte Authors > Edit cells > Join multi-valued cells... > Separator: |
Kleine Fingerübungen
- Spalte Licence > Facet > Text facet
- Was ist die am häufigsten vergebene Lizenz
- CC BY (954x)
- Wieviele Artikel haben keine Lizenz?
- 6
- Was ist die am häufigsten vergebene Lizenz
- Spalte Publisher > Facet > Text facet
- Warum erscheint MDPI AG zweimal?
- Eingabe einmal mit 1 Leerschlag, und einmal mit 2
- Wie lässt sich das korrigieren?
- Edit, Leerzeichen löschen und Apply klicken
- Cluster -> merge
- Warum erscheint MDPI AG zweimal?
Vorführung Reconciliation
- Ziel: Über die ISSN Informationen zur Zeitschrift ergänzen
- Spalte Citation > Edit column > Add column based on this column...
- Name: Journal
- Expression:
value.split(",")[0]
- Spalte Journal > Reconcile > Start reconciling
- Wikidata reconci.link (en) auswählen
- links "Reconcile against no particular type" auswählen
- rechts "ISSNs" aktivieren und in Textfeld ISSN eingeben und P236 anklicken
- Spalte Journal > Edit column > Add columns from reconciled values...
- official website (P856)
- configure: Limit auf 1 setzen
Übung: CSV nach MARCXML mit OpenRefine
- Wir nutzen die Funktion Templating Exporter. Diese findet sich oben rechts im Menü Export > Templating
- Beschreibung des MARC21 Formats für bibliografische Daten mit Liste der Felder: https://www.loc.gov/marc/bibliographic/
- Beispieldatei der Library of Congress für MARC21 mit mehreren Dokumenten: https://www.loc.gov/standards/marcxml/xml/collection.xml
Note:
- Das Vorgehen ist ähnlich wie bei XSLT Crosswalks, nur dass das "Template" hier direkt bearbeitet werden kann und nicht bereits fest steht, wie bei MarcEdit.
- OpenRefine verwendet eine eigene Template-Sprache (GREL) statt XSLT.
Voraussetzung für die Übung
- OpenRefine (lokal oder auf dem Server)
- Ein Projekt mit den Beispieldaten aus der Library Carpentry Lesson.
- Schnell neu zu erstellen mit: Create Project > Web Addresses (URL)
Vorlage als Ausgangsbasis
-
Prefix:
<collection xmlns="http://www.loc.gov/MARC21/slim"> -
Row Separator: (Zeilenumbruch)
-
Suffix:
</collection> -
Row Template:
<record> <leader> nab a22 uu 4500</leader> <controlfield tag="001">{{cells['URL'].value.replace('https://doaj.org/article/','').escape('xml')}}</controlfield> <datafield tag="022" ind1=" " ind2=" "> <subfield code="a">{{cells['ISSNs'].value.escape('xml')}}</subfield> </datafield> <datafield tag="100" ind1="0" ind2=" "> <subfield code="a">{{cells['Authors'].value.split('|')[0].escape('xml')}}</subfield> </datafield> <datafield tag="245" ind1="0" ind2="0"> <subfield code="a">{{cells["Title"].value.escape('xml')}}</subfield> </datafield>{{ forEach(cells['Authors'].value.split('|').slice(1), v ,' <datafield tag="700" ind1="0" ind2=" "> <subfield code="a">' + v.escape('xml') + '</subfield> </datafield>') }} </record>
Aufgabe 1: "Reverse Engineering"
- Beschreiben Sie anhand des Vergleichs der Ausgangsdaten mit dem Ergebnis mit ihren eigenen Worten welche Transformationen für die jeweiligen Felder durchgeführt wurden.
- Versuchen Sie die Aufgabe in der Gruppenarbeit zunächst einzeln zu lösen (10 min) und diskutieren Sie dann in der Gruppe.
- Dokumentieren Sie abschließend bitte hier das Gruppenergebnis.
Aufgabe 2: Template ergänzen
- Suchen Sie für weitere Spalten in den DOAJ-Daten die Entsprechung in MARC21: https://www.loc.gov/marc/bibliographic/
- Erstellen Sie geeignete Regeln im Template, um die Daten der gewählten Spalten in MARC21 zu transformieren.
- Dokumentieren Sie das gewählte MARC21-Feld und den zugehörigen Abschnitt aus dem Template.
- Wenn die Spalten leere Zellen enthalten, dann Funktion
forNonBlank()nutzen. Beispiel:
{{
forNonBlank(
cells['DOI'].value,
v,
'<datafield tag="024" ind1="7" ind2=" ">
<subfield code="a">' + v.escape('xml') + '</subfield>
<subfield code="2">doi</subfield>
</datafield>',
''
)
}}
Lösung aus der Vorführung
<record>
<leader> nab a22 uu 4500</leader>
<controlfield tag="001">{{cells['URL'].value.replace('https://doaj.org/article/','').escape('xml')}}</controlfield>
<datafield tag="022" ind1=" " ind2=" ">
<subfield code="a">{{cells['ISSNs'].value.escape('xml')}}</subfield>
</datafield>
<datafield tag="100" ind1="0" ind2=" ">
<subfield code="a">{{cells['Authors'].value.split('|')[0].escape('xml')}}</subfield>
</datafield>
<datafield tag="245" ind1="0" ind2="0">
<subfield code="a">{{cells["Title"].value.escape('xml')}}</subfield>
</datafield>
{{forEach(cells['Subjects'].value.split("|"), v,
'<datafield tag="650" ind1="0" ind2="4">
<subfield code="a">' + v.escape('xml') + '</subfield>
</datafield>' + '\n').join('')}}
{{
forEach(cells['Authors'].value.split('|').slice(1), v ,'
<datafield tag="700" ind1="0" ind2=" ">
<subfield code="a">' + v.escape('xml') + '</subfield>
</datafield>')
}}
</record>
Aufgabe 3: Validieren mit xmllint
- Wir exportieren das Gesamtergebnis als XML-Datei.
- Tipp: Firefox speichert Datei im Downloads-Ordner als .txt. Ordner Downloads aufrufen und Ende umbenennen in .xml
- Für die Validierung können Sie das Programm
xmllintverwenden, das unter Ubuntu vorinstalliert ist. - Zum Abgleich gegen das offizielle Schema von MARC21 laden wir dieses (XSD) zunächst herunter.
cd ~/Downloads
wget https://www.loc.gov/standards/marcxml/schema/MARC21slim.xsd
xmllint doaj-article-sample-csv.xml --noout --schema MARC21slim.xsd
Note:
- Wenn Sie für das Projekt in OpenRefine nicht den vorgeschlagenen Namen verwendet haben, heißt die gespeicherte Datei bei Ihnen anders.
OpenRefine beenden
- Im Terminalfenster
STRG+Cdrücken - Wenn wieder ein blinkender Cursor erscheint, kann das Terminalfenster geschlossen werden mit dem Befehl
exit
Aufgaben
Bis zum nächsten Termin:
- Beitrag im Lerntagebuch zu dieser Lehreinheit (3000 - 4000 Zeichen)
- Installation VuFind (siehe unten) bitte möglichst frühzeitig, damit wir bei Problemen noch unterstützen können
- Übung "Konfiguration Suche und Facetten" (siehe unten) und dazu einen Beitrag im Lerntagebuch verfassen (1000-2000 Zeichen)
Installation VuFind
Installation VuFind 8.0.2
Installation nach offizieller Anleitung für VuFind unter Ubuntu: https://vufind.org/wiki/installation:ubuntu
Es folgen die relevanten Auszüge und Hinweise/Erklärungen dazu.
VuFind on Ubuntu
These instructions assume that you are starting with a clean installation of Ubuntu. If you already have an Ubuntu server, you will be able to skip some steps, but you may have to reconfigure some existing software.
Zur Erinnerung: Best Practice ist die Installation von einer Anwendung pro Server (durch Virtualisierung und Container heute einfach möglich).
Version Requirements
These instructions were most recently tested on Ubuntu 20.04 (...)
Gut für uns, weil wir für unsere virtuelle Maschine Ubuntu 20.04 LTS verwenden.
Installing VuFind from the DEB Package
The easiest way to get VuFind up and running is to install it from the DEB package.
VuFind stellt ein Installationspaket bereit. Unter Linux gibt es viele verschiedene Formate für Installationspakete. Für Ubuntu und Debian gibt es DEB, für Fedora und SUSE beispielsweise RPM. Wir starten die Installation wie vorgegeben:
wget https://github.com/vufind-org/vufind/releases/download/v8.0.2/vufind_8.0.2.deb
sudo dpkg -i vufind_8.0.2.deb
Es erscheint eine Fehlermeldung, dass noch nicht alle von VuFind benötigten Pakete installiert sind. Zunächst aktualisieren wir das Paketverzeichnis (Nachtrag 14.12.):
sudo apt-get update
Dann lassen wir die benötigten Pakete mit installieren:
sudo apt-get install -f
Important Notes / Database Issues
Hier ist ein Fehler in der Anleitung. Ubuntu 20.04 wird mit MariaDB ausgeliefert und nicht mit MySQL. Für uns ist daher "Case 4 - MariaDB" relevant.
MariaDB Passwort für root
If you are using a distribution that includes MariaDB instead of MySQL, you will not be prompted to set a root password during installation. Instead, you should run “sudo /usr/bin/mysql_secure_installation” to properly set up security.
sudo /usr/bin/mysql_secure_installation
- Das aktuelle Passwort ist leer (Enter drücken).
- Neues Passwort vergeben (und merken!).
- Die voreingestellten Antworten sind OK (alle Fragen können mit Enter bestätigt werden).
MariaDB Zugriff auf root erlauben
(...) you may also need to disable the root account's “unix_socket” plugin, which prevents regular logins. You can do this by logging in with “sudo mysql -uroot -p” and then running "UPDATE mysql.user SET plugin='' WHERE User='root'; FLUSH PRIVILEGES;"
Der im Zitat beschriebene Weg würde funktionieren. Einfacher ist die Eingabe der SQL-Befehle als Einzeiler:
sudo mysql -uroot -p -e "UPDATE mysql.user SET plugin='' WHERE User='root'; FLUSH PRIVILEGES;"
Important Notes / (Ende)
You may want to restart your system one more time to be sure all the new settings are in place, or at least make sure appropriate environment variable settings are loaded by running:
source /etc/profile
Ein Neustart ist in unserem Fall nicht erforderlich. Es reicht aus, den genannten Befehl einzugeben:
source /etc/profile
Abweichend von der Installationsanleitung: Dateirechte anpassen
- Wir starten Solr gleich "von Hand", d. h. mit den Rechten des Accounts, mit dem wir gerade an der VM angemeldet sind. Die VuFind-Installation sieht jedoch vor, mit den Rechten des ersten regulären Accounts gestartet zu werden.
- Wir übertragen diese Rechte also nun auf unseren Account und belassen die Rechte für das Cache- und das Config-Verzeichnis beim Account des Webservers (www-data).
sudo chown -R $USER:$GROUP /usr/local/vufind
sudo chown -R www-data:www-data /usr/local/vufind/local/cache
sudo chown -R www-data:www-data /usr/local/vufind/local/config
Configuring and starting VuFind / Start solr
/usr/local/vufind/solr.sh start
Die Warnungen zu den Limits können erstmal ignoriert werden. In der Doku von VuFind ist beschrieben, wie sich das korrigieren ließe: https://vufind.org/wiki/administration:starting_and_stopping_solr
Configuring and starting VuFind / Configure VuFind
Open a web browser, and browse to this URL: http://your-server-name/vufind/Install/Home (Replace “your-server-name” with the address you wish to use to access VuFind; replace “vufind” with your custom base path if you changed the default setting during installation).
Wir haben keinen Domainnamen. Daher verwenden wir localhost. Öffnen Sie den Browser in der virtuellen Maschine (Linux) und rufen Sie die folgende Adresse auf:
http://localhost/vufind/Install/Home
Configuring and starting VuFind / Auto-Configuration
If installation was successful, you should now see an Auto Configure screen. Some items on the list will be marked “Failed” with “Fix” links next to them. Click on each Fix link in turn and follow the on-screen instructions. (...) After an issue is successfully resolved, you can click the “Auto Configure” breadcrumb to go back to the main list and proceed to the next problem.
Die meisten Punkte können ohne weitere Angaben "gefixt" werden. Nur die beiden Punkte Database und ILS erfordern weitere Angaben.
Configuring and starting VuFind / Auto-Configuration / Database
Bei der Datenbank muss ein neues Passwort vergeben sowie das zuvor oben im Abschnitt "MariaDB Passwort für root" eingegeben werden.
Configuring and starting VuFind / Auto-Configuration / ILS
Wir haben kein Bibliothekssystem, daher wählen wir NoILS. Dann wird aber trotzdem noch "Failed" angezeigt und wenn wir nochmal auf "Fix" klicken erscheint die folgende Meldung:
(...) You may need to edit the file at /usr/vufind/local/config/vufind/NoILS.ini
- Datei im Texteditor (gedit) mit Administratorrechten öffnen
sudo gedit /usr/local/vufind/local/config/vufind/NoILS.ini
- In Zeile 3
ils-offlineinils-noneändern und speichern.
Weitere Sicherheitseinstellungen
- Die in den Abschnitten Locking Down Configurations und 4. Secure your system beschriebenen Einstellungen benötigen wir für unsere Testinstallation nicht.
Fehlerbehebung
Falls etwas schief geht, können die folgenden Befehle helfen die Installation teilweise oder ganz zurückzusetzen.
Fall 1: Auto Configuration ist nicht mehr erreichbar
-
Problem: Die Seite "Auto Configuration" unter http://localhost/vufind/Install/Home war schon einmal aufrufbar, aber kann nun nicht mehr geladen werden.
-
Ursache: Die Konfiguration ist defekt und kann von VuFind nicht mehr gelesen werden.
-
Lösung:
-
Die lokale Konfiguration (im Verzeichnis /usr/local/vufind/local/) manuell löschen.
sudo rm /usr/local/vufind/local/config/vufind/config.ini -
Datenbank und Nutzer löschen (bei der folgenden Abfrage das Root-Passwort für MariaDB eingeben, das oben festgelegt wurde)
sudo mysql -uroot -p -e "DROP DATABASE IF EXISTS vufind; DROP USER IF EXISTS vufind@localhost;"
-
-
Danach die Seite "Auto Configuration" aufrufen und die Konfiguration erneut versuchen.
Fall 2: Auto Configuration kann gar nicht aufgerufen werden
-
Problem: Die Seite "Auto Configuration" http://localhost/vufind/Install/Home kann nicht aufgerufen werden oder liefert nur eine leere weiße Seite zurück.
-
Ursache: Bei der Installation ist etwas schief gegangen.
-
Lösung:
-
Installation von VuFind vollständig löschen
sudo dpkg -P vufindsudo rm -rf /usr/local/vufind sudo rm /etc/apache2/conf-enabled/vufind.conf -
Datenbank und Nutzer löschen (bei der folgenden Abfrage das Root-Passwort für MariaDB eingeben, das oben festgelegt wurde)
sudo mysql -uroot -p -e "DROP DATABASE IF EXISTS vufind; DROP USER IF EXISTS vufind@localhost;"
-
-
Danach Installation noch einmal ganz von vorne beginnen. Dabei Befehle Zeile für Zeile eingeben und auf Fehlermeldungen achten.
Fall 3: Root-Passwort für MariaDB vergessen
- Problem: Sie haben das Root-Passwort für MariaDB vergessen und können daher weder die "Auto Configuration" abschließen noch von vorne beginnen, weil sie die Datenbank von VuFind nicht löschen können.
- Fehlerbeschreibung: Der Aufruf der Befehle beginnend mit
sudo mysql -uroot -pschlägt bei der Passworteingabe fehl. - Lösung: Aus Sicherheitsgründen ist das Zurücksetzen des Root-Passworts für MariaDB etwas komplizierter. Folgen Sie diesem Tutorial bei Digital Ocean: How To Reset Your MySQL or MariaDB Root Password on Ubuntu 20.04
Testimport
-
Ohne Inhalte lässt sich VuFind schlecht erproben. Daher laden wir zunächst ein paar Daten in das System.
-
VuFind liefert für Tests einige Dateien mit. Wir laden einige davon im MARC21-Format.
/usr/local/vufind/import-marc.sh /usr/local/vufind/tests/data/journals.mrc /usr/local/vufind/import-marc.sh /usr/local/vufind/tests/data/geo.mrc /usr/local/vufind/import-marc.sh /usr/local/vufind/tests/data/authoritybibs.mrc -
Anschließend sollten in der Suchoberfläche unter http://localhost/vufind ca. 250 Datensätze enthalten sein.
Übung: Konfiguration Suche und Facetten
- Schauen Sie sich das offizielle Einführungsvideo Configuring Search and Facet Settings an.
- Ein Transkript ist auch auf der Seite https://vufind.org/wiki/videos:configuring_search_and_facet_settings verfügbar.
- Versuchen Sie ausgewählte Inhalte des Videos in Ihrer Installation nachzuvollziehen.
Note:
- Um die Bearbeitung der im Video benannten Konfigurationsdateien (.ini) zu erleichtern, können Sie die Dateiberechtigungen wie folgt ihrem Account zuordnen. Wir hatten diese für die Auto-Configuration beim Webserver (www-data) belassen.
sudo chown -R $USER:$GROUP /usr/local/vufind/local/config