Compare commits
201 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
2c8c8554a1 | ||
|
|
b8621bc96f | ||
|
|
b74f663f2a | ||
|
|
0ba01b97af | ||
|
|
2101d75ae5 | ||
|
|
40dfd1d680 | ||
|
|
a1bed65c4e | ||
|
|
15b7ce02cc | ||
|
|
08a02bf36b | ||
|
|
9138bb2ce1 | ||
|
|
55bc6115c1 | ||
|
|
4b9ca03461 | ||
|
|
26b1849865 | ||
|
|
adffca68db | ||
|
|
970f3de5f1 | ||
|
|
a0cb818eb9 | ||
|
|
c6012979ff | ||
|
|
792b1ac2e7 | ||
|
|
66d9c3f386 | ||
|
|
c2c39c92f9 | ||
|
|
a41c897d7b | ||
|
|
086021b698 | ||
|
|
07c8e09f32 | ||
|
|
2676c1e81b | ||
|
|
c8dd109902 | ||
|
|
7b6cb717c4 | ||
|
|
b6f09f6b5c | ||
|
|
8dcad5653c | ||
|
|
5e031a10e9 | ||
|
|
987aaa27f3 | ||
|
|
5e6683b881 | ||
|
|
7cd739b465 | ||
|
|
9a4d9de772 | ||
|
|
972730cadc | ||
|
|
7866873bc5 | ||
|
|
04d8748ef2 | ||
|
|
1ff51be895 | ||
|
|
dc1fa8c4bf | ||
|
|
5f7454c357 | ||
|
|
91b9acfd8d | ||
|
|
a98483331b | ||
|
|
52d8ef7f63 | ||
|
|
0cc5617bae | ||
|
|
273ccdc0f8 | ||
|
|
0aceaf4836 | ||
|
|
69b0203c6a | ||
|
|
cf1b86367b | ||
|
|
b9ac0235fb | ||
|
|
0953479793 | ||
|
|
3cdc597255 | ||
|
|
6142a653b5 | ||
|
|
6aa8fcfb4f | ||
|
|
1c32794d03 | ||
|
|
4e2b5feed0 | ||
|
|
9f7cec43aa | ||
|
|
58fc60c88d | ||
|
|
b44201333d | ||
|
|
32556e1f3c | ||
|
|
77be1b4aca | ||
|
|
55f38bbc4a | ||
|
|
d09cbc9c86 | ||
|
|
3a81d29335 | ||
|
|
7c47040f78 | ||
|
|
dcfbe54e28 | ||
|
|
7f482e3a6f | ||
|
|
2617f527c5 | ||
|
|
83819bbfca | ||
|
|
11f71311fe | ||
|
|
d7b78ee6c8 | ||
|
|
9178b55bb0 | ||
|
|
c305aeca13 | ||
|
|
8ee8d2e88f | ||
|
|
657f4bc155 | ||
|
|
d94ae9ca51 | ||
|
|
469e9ee681 | ||
|
|
aacc1c2a6f | ||
|
|
49c4a3bbcb | ||
|
|
a32b5b4f50 | ||
|
|
c8e9c729b0 | ||
|
|
8f20764b8a | ||
|
|
a393b18736 | ||
|
|
f3907b38b2 | ||
|
|
28aadc87f8 | ||
|
|
dfed333f09 | ||
|
|
5a766e5481 | ||
|
|
aae6483340 | ||
|
|
74574e671e | ||
|
|
4e7d52f36b | ||
|
|
9ac85233f4 | ||
|
|
7203ea49d1 | ||
|
|
a6b4380476 | ||
|
|
a0abc8bb4b | ||
|
|
798ddd0b2b | ||
|
|
cf217973a3 | ||
|
|
4c4a15b2b7 | ||
|
|
45f285a0a0 | ||
|
|
3cb769814b | ||
|
|
831b959613 | ||
|
|
038f95a51b | ||
|
|
149aa92334 | ||
|
|
ebc133ae0a | ||
|
|
5234055ee8 | ||
|
|
9e291f7563 | ||
|
|
db2a3f00bc | ||
|
|
4f91abcafb | ||
|
|
d8cacd9fa9 | ||
|
|
11f0aa9786 | ||
|
|
0f86bbe237 | ||
|
|
c15430a58f | ||
|
|
3bc52657ba | ||
|
|
2859c8cbae | ||
|
|
6e1f0b29ee | ||
|
|
5c26087ad7 | ||
|
|
7b7c072298 | ||
|
|
f86a50e6a4 | ||
| 26829ab465 | |||
|
|
f3004263a5 | ||
| 65acb2786e | |||
|
|
4f93b5cc93 | ||
|
|
f89a8ab627 | ||
|
|
8c9d130726 | ||
|
|
494e88371a | ||
|
|
a1284fd255 | ||
|
|
c2c5070b05 | ||
| 982d04a180 | |||
|
|
8e2b536403 | ||
|
|
6127b5d72f | ||
|
|
456e458d66 | ||
|
|
635fab4fed | ||
|
|
4169275975 | ||
|
|
003a620311 | ||
|
|
06bec526f4 | ||
|
|
91eb770bbc | ||
|
|
cadddbba8c | ||
|
|
622e702593 | ||
|
|
ca03654289 | ||
|
|
412200f0eb | ||
|
|
c62d3560a7 | ||
|
|
dc5ca64239 | ||
|
|
c3cbb59313 | ||
|
|
25e5ee53f9 | ||
|
|
5157c5b1e6 | ||
|
|
b6ee67986c | ||
|
|
3cec052076 | ||
|
|
4458435e73 | ||
|
|
685c287958 | ||
|
|
158fa02ca8 | ||
|
|
f0ddecbe60 | ||
|
|
b6078c67b2 | ||
|
|
8d602f823a | ||
|
|
967277e2df | ||
|
|
1974ec3497 | ||
|
|
33df15372a | ||
|
|
59b0138f70 | ||
|
|
5b0e0b38fd | ||
|
|
8674de4dbd | ||
|
|
0b2f04bbbd | ||
|
|
8056c7de4a | ||
|
|
dcfdab41fe | ||
|
|
8f17b63bb3 | ||
|
|
6bf75becd0 | ||
|
|
d94cd76652 | ||
|
|
e7315025ea | ||
|
|
730d97071f | ||
|
|
cf0553d8b6 | ||
|
|
9b434b62f8 | ||
|
|
f4db40843d | ||
|
|
5787e0d1c5 | ||
|
|
986515a78d | ||
|
|
c35df9d9fa | ||
|
|
b42cdbb167 | ||
|
|
b82af10126 | ||
|
|
1744878fa0 | ||
|
|
46f9ea9a4f | ||
|
|
61a8f5ad5f | ||
|
|
6b09c3f2cb | ||
|
|
f614230af6 | ||
|
|
576207a714 | ||
|
|
faff475592 | ||
|
|
0e52c49b37 | ||
|
|
0c8a9f5cce | ||
|
|
36e58ee77b | ||
|
|
f2ff641e9d | ||
|
|
f5d386399f | ||
|
|
ec0eb8e814 | ||
|
|
4037484275 | ||
|
|
29ff59fb64 | ||
|
|
72c99368c7 | ||
|
|
23513c8c5e | ||
|
|
fb252d0c99 | ||
|
|
739407f979 | ||
|
|
5b993f7ce0 | ||
|
|
1dafb124a5 | ||
|
|
fe1d769020 | ||
|
|
5d80340197 | ||
|
|
c0f730fa62 | ||
|
|
9f4d161b6c | ||
|
|
d59c61bf48 | ||
|
|
e57048e21f | ||
|
|
fc52719fda | ||
|
|
24e3c83c11 |
@ -1,138 +1,136 @@
|
||||
# Technische Grundlagen
|
||||
|
||||
* Schaubild zu Lehrinhalten
|
||||
* Einrichtung der Arbeitsumgebung (Linux)
|
||||
* Grundlagen der Unix Shell
|
||||
* Versionskontrolle mit Git
|
||||
* Versionskontrolle mit git
|
||||
* Blog mit GitHub Pages
|
||||
|
||||

|
||||
|
||||
erstellt mit [mermaid](https://mermaidjs.github.io/mermaid-live-editor/)
|
||||
|
||||
Note:
|
||||
- Den heutigen Tag werden wir vor allem mit allgemeinen technischen Grundlagen verbringen.
|
||||
- Als Arbeitsumgebung verwenden wir ein Linux-Betriebssystem auf einer virtuellen Maschine. Im [vorigen Semester](https://github.com/felixlohmeier/bibliotheks-und-archivinformatik/releases/tag/v1.0) wurden im Kurs BAIN die virtuellen Maschinen lokal auf den Laptops der Studierenden mit [VirtualBox](https://www.virtualbox.org) installiert. Dabei treten aber in 1-2 von 10 Fällen Probleme in Verbindung mit BIOS/UEFI-Einstellungen, Sicherheitsfeatures und teilweise vorinstallierten Windows-Services (Hyper-V) auf.
|
||||
- Die Unix Shell werden wir im Kurs öfter für Installation und Konfiguration der Software verwenden. Daher beginnen wir hier mit einer Wiederholung der wichtigsten Kommandos, damit uns das später leichter fällt.
|
||||
- Durch die Plattform GitHub, auf der Informatiker\*innen Ihren Quellcode ablegen, ist das Versionskontrollsystem Git sehr populär geworden. Es ist nicht nur für die Entwicklung von Software, sondern generell für die Zusammenarbeit in Projekten extrem hilfreich.
|
||||
- Die Übungen zu Unix Shell und Git basieren auf den Lehrmaterialien von [Library Carpentry](https://librarycarpentry.org/). Wer von Ihnen hat davon schon einmal gehört? Ggf. Lessons auf der Webseite zeigen.
|
||||
- In diesem Schaubild sind links die Lokalsysteme (Bibliothekssytem Koha, Archivinformationssystem ArchivesSpace, Repository-Software DSpace) aufgeführt. Diese bieten jeweils eine OAI-Schnittstelle an.
|
||||
- Mit einer speziellen Software (hier: VuFindHarvest) werden die Metadaten im jeweils spezifischen Format eingesammelt. Über einen XSLT Crosswalk werden die Daten dann einheitlich in MARC21-XML überführt. Zusätzlich werden Tabellendaten (CSV) mit OpenRefine ebenfalls in MARC21-XML transformiert.
|
||||
- Abschließend werden alle MARC21-XML-Daten in die Discovery-Lösung VuFind eingespielt.
|
||||
- Wir lernen die Systeme, Schnittstellen, Tools und Formate Schritt für Schritt kennen. Am Ende des Kurses sollten Sie das Schaubild dann in eigenen Worten erklären können.
|
||||
|
||||
## Einrichtung der Arbeitsumgebung (Linux)
|
||||
|
||||
* Wir verwenden virtuelle Maschinen der Cloud-Plattform Microsoft Azure.
|
||||
* Auf den virtuellen Maschinen ist das Linux-Betriebssystem [Ubuntu 19.10 Server](https://wiki.ubuntu.com/EoanErmine/ReleaseNotes) mit der Oberfläche [XFCE](https://www.xfce.org) installiert.
|
||||
* Sie erhalten alle eine eigene virtuelle Maschine, die Sie auch "kaputtspielen" dürfen.
|
||||
### Arbeitsumgebung
|
||||
|
||||
* Jede/r erhält eine virtuelle Maschine der FH Graubünden mit Ubuntu Linux.
|
||||
* Sie haben volle Administrationsrechte.
|
||||
* Dozenten haben zur Unterstützung und Fehlerbehebung ebenfalls Zugriff darauf.
|
||||
|
||||
### Linux
|
||||
|
||||
* Die meisten Webserver laufen auf Linux.
|
||||
* Wir verwenden [Ubuntu](https://ubuntu.com) in der Version 20.04 LTS.
|
||||
* Ubuntu basiert wiederum auf [Debian](https://www.debian.org). Die ganze Familiengeschichte: [GNU/Linux Distributions Timeline](https://upload.wikimedia.org/wikipedia/commons/1/1b/Linux_Distribution_Timeline.svg)
|
||||
|
||||
Note:
|
||||
- Normalerweise werden Linux-Server aus Sicherheitsgründen ohne grafische Oberfläche administriert, also nur über die Kommandozeile. Wir verwenden hier XFCE (extra leichtgewichtig, es gibt hübschere Linux-Desktops...), um den Einstieg zu erleichtern.
|
||||
- "Kaputtspielen" bedeutet, dass die virtuelle Maschine einfach von mir auf den Ausgangszustand zurückgesetzt werden kann, wenn etwas schief geht. Scheuen Sie sich also nicht davor etwas auszuprobieren.
|
||||
- Ausschlaggebende Gründe für Verwendung von [Microsoft Azure Lab Services](https://azure.microsoft.com/de-de/services/lab-services/) gegenüber anderen Plattformen:
|
||||
- Studierende müssen nur wenig Daten preisgeben (Microsoft-Konto, aber keine Zahlungsdaten)
|
||||
- Studierende können virtuelle Maschinen über eine einfach gehaltene Oberfläche selbst starten und stoppen.
|
||||
- Kosten entstehen nur für tatsächlich genutzte Zeit und nicht im ausgeschalteten Zustand.
|
||||
- Anleitung für Lehrende: [Azure Lab einrichten](https://bain.felixlohmeier.de/#/azure-lab-einrichten)
|
||||
- Normalerweise werden Linux-Server aus Sicherheitsgründen ohne grafische Oberfläche administriert, also nur über die Kommandozeile.
|
||||
|
||||
### Registrierung im Lab
|
||||
### Zugriff auf die virtuelle Maschine
|
||||
|
||||
* Sie erhalten jetzt einen Registrierungslink an Ihre E-Mail-Adresse.
|
||||
* Nach Login unter <https://labs.azure.com> sollte es so ähnlich aussehen:
|
||||

|
||||
1. Mit dem Netzwerk der FHGR verbinden (ggf. via VPN)
|
||||
2. <https://horizon.fhgr.ch> aufrufen
|
||||
3. Zugriff auf die virtuelle Maschine (Ubuntu) entweder direkt über den Browser (HTML5) oder über eine Zusatzsoftware (Horizon Client)
|
||||
|
||||
Sie können sich an allen drei Punkten (VPN, Horizon und Ubuntu) mit Ihrem persönlichen FHGR-Konto anmelden. Achtung: Beim Anmeldebildschirm von Ubuntu ist ein US-Tastaturlayout eingestellt.
|
||||
|
||||
Note:
|
||||
- Memo für Lehrende: Jetzt in Azure Lab Services einloggen, alle VMs starten und Registrierungslinks versenden.
|
||||
- Es ist erforderlich, dass Sie im Zuge der Registrierung ein persönliches Microsoft-Konto einrichten oder ihre E-Mail-Adresse mit einem vorhandenen persönlichen Microsoft-Konto verbinden. Das lässt sich leider nicht vermeiden. Es müssen dabei E-Mail, Name und Geburtsdatum angegeben werden.
|
||||
- Falls Sie nach dem Login erneut auf der Startseite der Lab Services landen:
|
||||
* Abmelden
|
||||
* Browser schließen
|
||||
* Browser neu starten
|
||||
* Seite <https://labs.azure.com> aufrufen und erneut anmelden.
|
||||
- Bei Wikimedia Commons gibt es ein Bild des US-Tastaturlayouts: <https://commons.wikimedia.org/wiki/File:KB_United_States.svg>
|
||||
- Copy & Paste funktioniert zuverlässiger mit der Zusatzsoftware.
|
||||
|
||||
### Verbindung mit der VM
|
||||
### Übung: Verbindung testen
|
||||
|
||||
* Nachdem die Virtuelle Maschine (VM) gestartet wurde (2-3 Minuten), können Sie über das kleine Bildschirm-Symbol die Zugangsdaten für Remote Desktop (RDP) laden.
|
||||
* Beim ersten Aufruf müssen Sie ein Passwort vergeben.
|
||||
* RDP-Datei öffnen mit:
|
||||
* Windows: Remote Desktop (vorinstalliert)
|
||||
* macOS: [Microsoft Remote Desktop 10](https://apps.apple.com/de/app/microsoft-remote-desktop-10/id1295203466) (siehe auch [Anleitung von Microsoft für macOS](https://docs.microsoft.com/de-de/azure/lab-services/classroom-labs/how-to-use-classroom-lab#connect-to-a-vm-using-rdp-on-a-mac))
|
||||
* Linux: [Remmina](https://remmina.org/)
|
||||
Bitte verbinden Sie sich jetzt mit der virtuellen Maschine. Nach dem Login sollte es etwa so aussehen:
|
||||
|
||||

|
||||
|
||||
### Grundeinstellungen
|
||||
|
||||
1. Favoriten
|
||||
* Unten links Anwendungsmenü öffnen
|
||||
* Programm suchen (`Terminal` und `Text Editor`)
|
||||
* Rechtsklick auf Icon und `Add to Favorites` wählen
|
||||
|
||||
2. Startseite im Firefox Browser
|
||||
* Die Übersichtsseite des gemeinsamen Dokuments aufrufen
|
||||
* Über das Sternchen in der Adressleiste ein Lesezeichen setzen
|
||||
|
||||
Note:
|
||||
- Während der Unterrichtszeiten starte und stoppe ich die VMs zentral.
|
||||
- Bei der Verbindung von Zuhause denken Sie bitte daran, die Maschine nach der Verwendung zu stoppen, damit keine unnötigen Kosten anfallen.
|
||||
- Das Passwort können Sie über das Zusatzmenü (drei kleine Punkte) jederzeit neu setzen.
|
||||
|
||||
### Login (Linux)
|
||||
|
||||

|
||||
|
||||
Note:
|
||||
- Benutzername: `bain`
|
||||
- Passwort: (haben Sie beim ersten Start festgelegt)
|
||||
|
||||
### Orientierung (Linux)
|
||||
|
||||

|
||||
|
||||
Note:
|
||||
- Ubuntu Server 19.10 mit XFCE
|
||||
- Benötigte Programme unten im Dock:
|
||||
1. Terminal
|
||||
2. Dateimanager (ähnlich Windows Explorer)
|
||||
3. Firefox-Browser
|
||||
4. Texteditor "Mousepad" (ähnlich Windows Notepad)
|
||||
- Herunterfahren über die Azure Labs Oberfläche unter <https://labs.azure.com> (ein `sudo poweroff` im Terminal reicht nicht aus)
|
||||
- Teilnehmer\*innen mit Mac? Dann im Applikationsmenü "Region & Language" das Keyboard Layout "German (Switzerland, Macintosh)" ergänzen und auswählen
|
||||
|
||||
## Grundlagen der Unix Shell
|
||||
|
||||
* Wird benötigt zur Administration von Servern
|
||||
* Ist aber auch zur Automatisierung von kleineren Aufgaben beliebt (Shell-Scripte)
|
||||
* Mit der Unix Shell lässt sich sogar "Text Mining" betreiben (dazu später eine kleine Übung)
|
||||
|
||||
### Download Materialien
|
||||
Note:
|
||||
- Die Unix Shell werden wir im Kurs öfter für Installation und Konfiguration der Software verwenden. Daher beginnen wir hier mit einer Wiederholung der wichtigsten Kommandos, damit uns das später leichter fällt.
|
||||
- Es gibt verschiedene Varianten der Shell. Ubuntu verwendet Bash.
|
||||
|
||||
### Download der Materialien
|
||||
|
||||
1. In das Home-Verzeichnis wechseln
|
||||
|
||||
```shell
|
||||
cd
|
||||
```
|
||||
```shell
|
||||
cd
|
||||
```
|
||||
|
||||
2. Archiv shell-lesson.zip von Library Carpentry herunterladen
|
||||
|
||||
```shell
|
||||
wget https://librarycarpentry.org/lc-shell/data/shell-lesson.zip
|
||||
```
|
||||
```shell
|
||||
wget https://librarycarpentry.org/lc-shell/data/shell-lesson.zip
|
||||
```
|
||||
|
||||
3. Archiv in den Ordner shell-lesson entpacken und Archiv löschen
|
||||
|
||||
```shell
|
||||
unzip shell-lesson.zip -d shell-lesson
|
||||
rm shell-lesson.zip
|
||||
```
|
||||
```shell
|
||||
unzip shell-lesson.zip -d shell-lesson
|
||||
rm shell-lesson.zip
|
||||
```
|
||||
|
||||
### Übungen
|
||||
|
||||
Bitte bearbeiten Sie zur Auffrischung Ihrer Shell-Kenntnisse die Kapitel 2 und 3 der Library Carpentry Lesson:
|
||||
* Kapitel 2: <https://librarycarpentry.org/lc-shell/02-navigating-the-filesystem/>
|
||||
* Kapitel 3: <https://librarycarpentry.org/lc-shell/03-working-with-files-and-folders/>
|
||||
Aufgaben:
|
||||
|
||||
### Tipps
|
||||
1. Bearbeiten Sie das zweite Kapitel [Navigating the filesystem](https://librarycarpentry.org/lc-shell/02-navigating-the-filesystem/index.html) der Library Carpentry Lesson zur Unix Shell
|
||||
2. Bearbeiten Sie das dritte Kapitel [Working with files and directories](https://librarycarpentry.org/lc-shell/03-working-with-files-and-folders/index.html) der Library Carpentry Lesson zur Unix Shell
|
||||
|
||||
* Nutzen Sie immer die Tab-Taste für die Autovervollständigung
|
||||
* Seien Sie faul, verwenden Sie Ihre persönliche Befehlshistorie (Pfeiltaste nach oben / Suche in der Historie mit `STRG`+`R`)
|
||||
### Tipps zur Unix Shell
|
||||
|
||||
* Copy & Paste im Terminal mit Rechtsklick oder STRG+SHIFT+C und STRG+SHIFT+V
|
||||
* Nutzen Sie immer die Tab-Taste für die Autovervollständigung.
|
||||
* Seien Sie faul, verwenden Sie Ihre persönliche Befehlshistorie (Pfeiltaste nach oben / Suche in der Historie mit `STRG`+`R`).
|
||||
* Wichtig ist die Unterscheidung zwischen Programm (`ls`) und Parametern (`-l`).
|
||||
* Nutzen Sie Spickzettel für die wichtigsten Kommandos wie z.B. [Library Carpentry Reference](https://librarycarpentry.org/lc-shell/reference.html) oder [Cheatsheet für Shell-Scripte](https://devhints.io/bash)
|
||||
* Nutzen Sie Spickzettel für die wichtigsten Kommandos wie z.B. [Library Carpentry Reference](https://librarycarpentry.org/lc-shell/reference.html) oder [Cheatsheet für Shell-Scripte](https://devhints.io/bash).
|
||||
|
||||
Note:
|
||||
- Alle Programme in der Unix Shell sind ähnlich aufgebaut. Wenn Sie das Grundprinzip mit der Unterscheidung von Programm und Parametern verinnerlicht haben, dann hilft Ihnen auch die integrierte Hilfe (`--help`) weiter.
|
||||
- Linux hat ein integriertes Nutzerhandbuch, das zu beinahe jedem Kommando und Programm hilfreiche Dokumentation enthält: man <command> (auch via Google)
|
||||
|
||||
### Redirects und Pipes
|
||||
|
||||
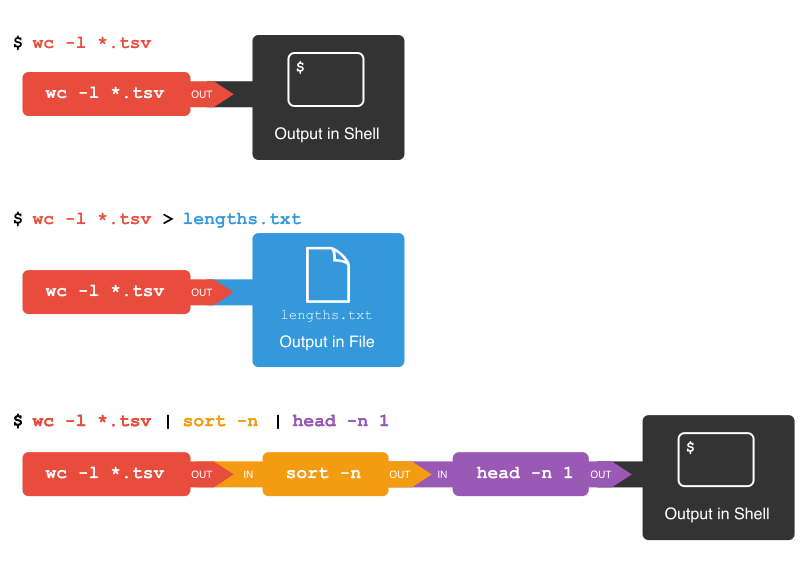
|
||||

|
||||
|
||||
Note:
|
||||
1. Bei einer normalen Eingabe landet das Ergebnis im Terminal. `wc` steht für "word count" und liefert mit dem Parameter `-l` die Anzahl der Zeilen. Die Angabe `*.tsv` bedeutet alle Dateien mit der Dateiendung "tsv".
|
||||
2. Stattdessen kann das Ergebnis aber auch in eine Datei umgelenkt werden mit der spitzen Klammer `>`
|
||||
3. Das Ergebnis eines Programms kann mit "Pipes" (`|`) direkt weiterverarbeitet werden. Welche Ausgabe erwarten Sie?
|
||||
|
||||
## Versionskontrolle mit Git
|
||||
## Versionskontrolle mit git
|
||||
|
||||
* Aus Zeitgründen schauen wir uns nur kurz gemeinsam einige Grundfunktionen von `git` an.
|
||||
* Aus Zeitgründen schauen wir uns nur Grundfunktionen von `git` an.
|
||||
* Wenn Sie im Anschluss selbst üben möchten, bietet Library Carpentry dazu [ausführliche Lehrmaterialien](<https://librarycarpentry.org/lc-git/>)
|
||||
|
||||
Note:
|
||||
- Durch die Plattform GitHub, auf der Informatiker\*innen Ihren Quellcode ablegen, ist das Versionskontrollsystem Git sehr populär geworden. Es ist nicht nur für die Entwicklung von Software, sondern generell für die Zusammenarbeit in Projekten extrem hilfreich.
|
||||
|
||||
### Wozu Git?
|
||||
|
||||
* Git ist eine Software zur Versionskontrolle
|
||||
@ -146,7 +144,7 @@ Note:
|
||||
### Unterschied Git und GitHub
|
||||
|
||||
* Git kann zunächst auch lokal auf einem Computer verwendet werden.
|
||||
* Wenn ein Git Repository im Netz bereitgestellt werden soll, braucht es eine Installation von git auf einem Webserver.
|
||||
* Wenn ein Git Repository im Netz bereitgestellt werden soll, braucht es eine Installation von Git auf einem Webserver.
|
||||
* Das kann man selber machen oder eine Plattform nutzen. Die bekannteste ist [GitHub](https://www.github.com).
|
||||
|
||||
Note:
|
||||
@ -154,123 +152,143 @@ Note:
|
||||
- Alternativen zu GitHub sind unter anderem [GitLab](https://gitlab.com), [BitBucket](https://bitbucket.org) oder auch das Urgestein [SourceForge](https://sourceforge.net).
|
||||
- Viele Bibliotheken nutzen GitHub oder GitLab. Es gibt eine gemeinschaftlich gepflegte Liste [BibsOnGitHub](https://github.com/axel-klinger/BibsOnGitHub), auf der [Listen von Bibliotheken](https://axel-klinger.github.io/BibsOnGitHub/libraries.html) und [deren Repositorien](https://axel-klinger.github.io/BibsOnGitHub/repositories.html) eingesehen werden können.
|
||||
|
||||
### Vorführung Grundfunktionen
|
||||
### Programme installieren
|
||||
|
||||
* Als Beispiel nutzen wir das GitHub Repository für diesen Kurs, in dem die Lehrmaterialien liegen: <https://github.com/felixlohmeier/bibliotheks-und-archivinformatik>
|
||||
* Zur Vorführung machen wir jetzt Folgendes:
|
||||
1. Die Dateien aus dem GitHub Repository herunterladen ("klonen")
|
||||
2. Eine der Textdateien verändern
|
||||
3. Die Änderung mit einer erläuternden Notiz hochladen
|
||||
1. Verzeichnis aktualisieren
|
||||
|
||||
#### Repository klonen
|
||||
```shell
|
||||
sudo apt update
|
||||
```
|
||||
|
||||
2. Programme installieren
|
||||
|
||||
```shell
|
||||
sudo apt install git curl
|
||||
```
|
||||
|
||||
Note:
|
||||
- Darauf folgt eine Passwortabfrage (nochmal das gleiche)
|
||||
- Änderungen werden komplex angezeigt, diese müssen dann nochmal mit `Y` (oder Enter) bestätigt werden
|
||||
- Die Paketverwaltung unter Linux ist vergleichbar mit einem App-Store von Apple oder Google
|
||||
|
||||
### Übung: Link zum Lerntagebuch ergänzen
|
||||
|
||||
* Als Beispiel nutzen wir das [GitHub Repository dieses Kurses](https://github.com/felixlohmeier/bibliotheks-und-archivinformatik), in dem die Lehrmaterialien liegen.
|
||||
* Sie ergänzen darin den Link zu Ihrem Lerntagebuch.
|
||||
* So gehen wir vor:
|
||||
1. Kopie des Repositories erstellen ("Fork")
|
||||
2. Dateien aus Ihrem Fork herunterladen ("clone")
|
||||
3. Link zu Ihrem Lerntagebuch in `README.md` einfügen
|
||||
4. Die Änderung mit einer Notiz hochladen ("commit")
|
||||
5. Übernahme der Änderung anfragen ("Pull request")
|
||||
|
||||
### Schritt 0: Git konfigurieren
|
||||
|
||||
Name und E-Mail für Git hinterlegen
|
||||
|
||||
```shell
|
||||
git clone https://github.com/felixlohmeier/bibliotheks-und-archivinformatik.git
|
||||
git config --global user.name "Felix Lohmeier"
|
||||
git config --global user.email "mail@felixlohmeier.de"
|
||||
```
|
||||
|
||||

|
||||
Note:
|
||||
- Ersetzen Sie die Angaben durch Ihre eigenen und verwenden Sie dieselbe E-Mail-Adresse, mit der Sie sich bei GitHub registriert haben. Dadurch kann GitHub Ihnen alle Änderungen zuordnen.
|
||||
- Die Konfiguration ist nur einmalig nötig. Sie wird in Ihrem Home-Verzeichnis gespeichert (```~/.gitconfig```) und künftig für jedes Repository automatisch als Standard verwendet.
|
||||
|
||||
#### Änderung mit Texteditor
|
||||
#### Schritt 1: Kopie des Repositories erstellen
|
||||
|
||||
* Bei GitHub einloggen
|
||||
* Repository aufrufen: <https://github.com/felixlohmeier/bibliotheks-und-archivinformatik>
|
||||
* Oben rechts auf Button "Fork" klicken
|
||||
|
||||
#### Schritt 2: Dateien herunterladen
|
||||
|
||||
Um die Dateien aus Ihrem Fork herunterzuladen ("klonen") geben Sie den folgenden Befehl ins Terminal ein.
|
||||
|
||||
Ersetzen Sie dabei `...` durch den Link zu Ihrem Fork.
|
||||
|
||||
```shell
|
||||
git clone ...
|
||||
```
|
||||
|
||||
Wechseln Sie in das erstellte Verzeichnis.
|
||||
|
||||
```shell
|
||||
cd bibliotheks-und-archivinformatik
|
||||
nano 01_technische-grundlagen.md
|
||||
```
|
||||
|
||||

|
||||
#### Schritt 3: Änderung lokal durchführen
|
||||
|
||||
Note:
|
||||
* Beim Aufruf des Programms nano wird das Terminal zu einem Texteditor.
|
||||
* Wir ergänzen eine Zeile in das leere Skript "Dies ist ein Test!"
|
||||
* Speichern und Verlassen des Texteditors
|
||||
* `STRG`+`X`
|
||||
* `y` ("yes" zu "save modified buffer"?)
|
||||
* Dateiname bestätigen zum Überschreiben der Datei
|
||||
1. Datei `README.md` in Texteditor öffnen und Link zu Ihrem Lerntagebuch in Abschnitt "Lerntagebücher" einfügen.
|
||||
|
||||
#### Änderung anzeigen
|
||||
2. Lassen Sie sich von `git` die Änderungen anzeigen:
|
||||
|
||||
```shell
|
||||
git diff
|
||||
```
|
||||
```shell
|
||||
git diff
|
||||
```
|
||||
|
||||

|
||||
3. Lassen Sie sich von `git` die geänderten Dateien anzeigen:
|
||||
|
||||
#### Lokaler Status
|
||||
```shell
|
||||
git status
|
||||
```
|
||||
|
||||
```shell
|
||||
git status
|
||||
```
|
||||
#### Schritt 4: Änderung hochladen
|
||||
|
||||

|
||||
1. Datei zum Päckchen hinzufügen
|
||||
|
||||
#### Datei zum Päckchen hinzufügen
|
||||
```shell
|
||||
git add README.md
|
||||
```
|
||||
|
||||
```shell
|
||||
git add 01_technische-grundlagen.md
|
||||
git status
|
||||
```
|
||||
2. Absender eintragen (mit Ihren Daten ersetzen)
|
||||
|
||||

|
||||
```shell
|
||||
git config user.email "mail@felixlohmeier.de"
|
||||
git config user.name "Felix Lohmeier"
|
||||
```
|
||||
|
||||
#### Absender eintragen
|
||||
3. Packzettel beilegen und Päckchen schließen
|
||||
|
||||
```shell
|
||||
git config user.email "mail@felixlohmeier.de"
|
||||
git config user.name "Felix Lohmeier"
|
||||
```
|
||||
```shell
|
||||
git commit -m "Link zu meinem Lerntagebuch"
|
||||
```
|
||||
|
||||

|
||||
4. Päckchen abschicken
|
||||
|
||||
Note:
|
||||
* Es werden Schreibrechte für das Git Repository benötigt, um Änderungen direkt einbringen zu können. Die Authentifizierung erfolgt über die E-Mail-Adresse.
|
||||
* Falls man keine Schreibrechte hat, kann man aber eine Kopie (Fork) erstellen, darein schreiben und anschließend einen sogenannten "Pull Request" stellen. Die Besitzerin des ursprünglichen Repositorys erhält dann eine Benachrichtigung und kann die Änderung übernehmen oder ablehnen. Das üben wir zum nächsten Termin.
|
||||
```shell
|
||||
git push
|
||||
```
|
||||
|
||||
#### Packzettel beilegen und Päckchen schließen
|
||||
#### Schritt 5: Pull Request erstellen
|
||||
|
||||
```shell
|
||||
git commit -m "Test Päckchen"
|
||||
```
|
||||
|
||||

|
||||
|
||||
#### Päckchen abschicken
|
||||
|
||||
```shell
|
||||
git status
|
||||
git push
|
||||
```
|
||||
|
||||

|
||||
* Mit wenigen Sekunden Verzögerung sollte Ihre Änderung nun auch bei GitHub angekommen sein.
|
||||
* Öffnen Sie Ihren Fork bei GitHub.
|
||||
* Klicken Sie auf den Link "Pull request". Dann erscheint ein Vergleich. Klicken Sie dort auf den Button "Create pull request".
|
||||
* Vervollständigen Sie das Formular und klicken Sie auf den Button "Create pull request".
|
||||
|
||||
#### Ergebnis auf GitHub
|
||||
|
||||
[Das Päckchen ("commit") bei GitHub](https://github.com/felixlohmeier/bibliotheks-und-archivinformatik/commit/caa6dc8dd640e0d1df86780288f84e0c47b81bef)
|
||||
Sie finden Ihren Pull Request im ursprünglichen Repository bei GitHub im Tab "Pull requests": <https://github.com/felixlohmeier/bibliotheks-und-archivinformatik/pulls>
|
||||
|
||||

|
||||
### Wofür git in Bibliotheken und Archiven?
|
||||
|
||||
### Blog mit GitHub Pages
|
||||
* Arbeitsfeld "forschungsnahe Dienste", siehe Positionspapier der Kommission für forschungsnahe Dienste des VDB: https://www.o-bib.de/article/view/5718/8434
|
||||
* siehe auch "Uses in a library context" in [Library Carpentry Lesson zu git](https://librarycarpentry.org/lc-git/01-what-is-git/index.html): "Local library looking to start a crowdsourcing project" und "Multiple people editing metadata for a collection"
|
||||
|
||||
## Blog mit GitHub Pages
|
||||
|
||||
* Mit GitHub Pages lassen sich statische Webseiten direkt aus den Dateien im GitHub Repository generieren und auf Servern von GitHub kostenfrei veröffentlichen.
|
||||
* GitHub verwendet dazu den (hauseigenen) Static-Site-Generator [Jekyll](https://help.github.com/en/github/working-with-github-pages/about-github-pages-and-jekyll).
|
||||
* Die Software nimmt Markdown- und HTML-Dateien und generiert daraus eine komplette Webseite.
|
||||
* Die Darstellung (Themes) lässt sich über eine Konfigurationsdatei einstellen.
|
||||
* [Vorlage für ein Lerntagebuch mit GitHub Pages](https://github.com/felixlohmeier/lerntagebuch) (mit Schritt-für-Schritt-Anleitung)
|
||||
* Siehe auch: [Interaktives Tutorial von GitHub](https://lab.github.com/githubtraining/github-pages)
|
||||
|
||||
### Übung: Pull Requests
|
||||
## Aufgaben
|
||||
|
||||
**Aufgabe (10 Minuten):** Link zum Lerntagebuch im Skript ergänzen
|
||||
Bis zum nächsten Termin:
|
||||
|
||||
1. Fork von Repository https://github.com/felixlohmeier/bibliotheks-und-archivinformatik erstellen ([Direktlink](https://github.com/felixlohmeier/bibliotheks-und-archivinformatik/fork ))
|
||||
2. Datei `README.md` in Ihrem Fork bearbeiten und Link zu Ihrem Lerntagebuch in [Abschnitt "Lerntagebücher"](https://github.com/felixlohmeier/bibliotheks-und-archivinformatik/blob/master/README.md#lerntageb%C3%BCcher) ergänzen
|
||||
3. Pull Request erstellen
|
||||
|
||||
Siehe auch: [Anleitung von GitHub](https://help.github.com/en/github/collaborating-with-issues-and-pull-requests/creating-a-pull-request-from-a-fork)
|
||||
|
||||
### Alternative zu GitHub: GitLab
|
||||
|
||||
* GitLab wird von einem kleinen Unternehmen entwickelt
|
||||
* basiert ebenfalls auf der Software git
|
||||
* Hat eine vergleichbare Funktion zu GitHub Pages: [GitLab Pages](https://docs.gitlab.com/ce/user/project/pages/)
|
||||
* Kann auf einem eigenen Server installiert werden
|
||||
* Vergleich von GitHub und GitLab: <https://www.heise.de/tipps-tricks/GitHub-vs-GitLab-4597154.html>
|
||||
1. Lerntagebuch einrichten
|
||||
* Vorlage für ein Lerntagebuch mit GitHub Pages: <https://github.com/felixlohmeier/lerntagebuch>
|
||||
* Link bitte auf der Übersichtsseite der gemeinsamen Dokumente ergänzen
|
||||
2. Einführungsartikel (wo bin ich gestartet?) (3000 - 4000 Zeichen)
|
||||
3. Beitrag zu dieser Lehreinheit "Technische Grundlagen" (3000 - 4000 Zeichen)
|
||||
|
||||
@ -2,34 +2,31 @@
|
||||
|
||||
* Metadatenstandards in Bibliotheken (MARC21)
|
||||
* Installation und Konfiguration von Koha
|
||||
* Cloud-Konzepte am Beispiel von ALMA
|
||||
* Marktüberblick Bibliothekssysteme
|
||||
|
||||
## Metadatenstandards in Bibliotheken (MARC21)
|
||||
|
||||
* MARC21: International verbreiteter Metadaten-Standard, begründet von der Library of Congress 1999: <https://www.loc.gov/marc/bibliographic/>
|
||||
* Hat ein [eigenes Binärformat](http://format.gbv.de/marc/iso) (.mrc), gibt's aber auch [als XML](http://format.gbv.de/marc/xml)
|
||||
* Hat [eigenes Binärformat](http://format.gbv.de/marc/iso) (.mrc), gibt's aber auch [als XML](http://format.gbv.de/marc/xml)
|
||||
* wegen unterschiedlicher Katalogisierungsregeln und der Möglichkeit eigene Felder zu belegen, weicht die Verwendung international und auch nach Institution [stark vom vermeintlichen Standard ab](https://docs.google.com/presentation/d/e/2PACX-1vRU4J_rln00UVD7pNPT0_02NOad0HfSk_UKqRI0v29y8QkMAplEDlyjc0Ot_VE_paV6WBW29Fh_V-iN/pub?start=false&loop=false&delayms=3000#slide=id.g574306292a_0_35)
|
||||
* wird zukünftig voraussichtlich von [BIBFRAME](http://format.gbv.de/bibframe), einem Datenmodell basierend auf [RDF](http://format.gbv.de/rdf), abgelöst
|
||||
* Koha und alle anderen großen Bibliothekssysteme basieren auf MARC21 oder unterstützen es als Austauschformat
|
||||
* wird zukünftig voraussichtlich von [BIBFRAME](http://format.gbv.de/bibframe), einem Datenmodell basierend auf [RDF](http://format.gbv.de/rdf), abgelöst
|
||||
|
||||
### Übung: Vergleich MARC21 und Dublin Core
|
||||
|
||||
* Dublin Core ist ein Standard, der als kleinster gemeinsamer Nenner gilt
|
||||
* Als Beispiele nutzen wir den Katalog der Bibliothek der FH Graubünden
|
||||
* Wir beziehen die Daten über die SRU-Schnittstelle von Swissbib (auf das Thema Schnittstellen und SRU gehen wir an einem anderen Tag noch ein)
|
||||
* Wir beziehen die Daten über die SRU-Schnittstelle von Swisscovery (auf das Thema Schnittstellen und SRU gehen wir an einem anderen Tag noch ein)
|
||||
|
||||
**Aufgabe (15 Minuten):** Laden Sie über das Formular auf der Webseite http://sru.swissbib.ch Daten mit den folgenden Parametern einmal im Format MARC21 und einmal im Format Dublin Core und vergleichen Sie diese.
|
||||
**Aufgabe (15 Minuten):** Laden Sie über die folgenden Links Daten über die SRU-Schnittstelle von Swisscovery einmal im Format MARC21 und einmal im Format Dublin Core und vergleichen Sie diese.
|
||||
|
||||
| Searchfield | value |
|
||||
| ------------------------ | ------------- |
|
||||
| dc.possessingInstitution | `E27` |
|
||||
| dc.title | `open access` |
|
||||
* MARC21: <https://swisscovery.slsp.ch/view/sru/41SLSP_NETWORK?version=1.2&operation=searchRetrieve&query=title=einstein&recordSchema=marcxml>
|
||||
* Dublin Core: <https://swisscovery.slsp.ch/view/sru/41SLSP_NETWORK?version=1.2&operation=searchRetrieve&query=title=einstein&recordSchema=dc>
|
||||
|
||||
Note:
|
||||
|
||||
- Das Projekt Swissbib sammelt Metadaten aller schweizer Universitätsbibliotheken, der Nationalbibliothek und einiger Kantonsbibliotheken sowie weiterer Institutionen.
|
||||
- Der gemeinsame Katalog ermöglicht eine übergreifende Suche, gleichzeitig bietet Swissbib auch Schnittstellen an, über welche Metadaten der teilnehmenden Institutionen zentral bezogen werden können.
|
||||
- Siehe auch: [Dokumentation Swissbib SRU](http://www.swissbib.org/wiki/index.php?title=SRU)
|
||||
- Der Katalog Swisscovery beinhaltet die Daten der an SLSP teilnehmenden Bibliotheken.
|
||||
- Der gemeinsame Katalog ermöglicht eine übergreifende Suche, gleichzeitig bietet Swisscovery auch Schnittstellen an, über welche Metadaten der teilnehmenden Institutionen zentral bezogen werden können.
|
||||
- Siehe auch: [Nutzung SLSP-Metadaten](https://slsp.ch/de/metadata), [Dokumentation der SRU-Schnittstelle von ALMA](https://developers.exlibrisgroup.com/alma/integrations/sru/)
|
||||
|
||||
## Installation und Konfiguration von Koha
|
||||
|
||||
@ -39,64 +36,97 @@ Note:
|
||||
* Weltweites Open Source Projekt, gegründet 1999 in Neuseeland, heute mit Beteiligung von Unternehmen wie ByWater Solutions, Biblibre, Catalyst IT, PTFS Europe, Theke Solutions
|
||||
* Status des Projekts: Siehe [Statistik bei Open Hub](https://www.openhub.net/p/koha)
|
||||
|
||||
Note:
|
||||
- Zur Gesundheit von Open-Source-Projekten siehe auch <https://felixlohmeier.de/slides/2017-09-28_vufind-anwendertreffen-keynote.html>
|
||||
- Zur Bedeutung von Open-Source-Software auch dieser Comic: <https://xkcd.com/2347/>
|
||||
|
||||
#### Koha Dokumentation
|
||||
|
||||
* Professionelle Entwicklungsstrukturen, vgl. Dashboard: <https://dashboard.koha-community.org>
|
||||
* Release Notes zur Version 19.11: <https://koha-community.org/koha-19-11-release/>
|
||||
* Handbuch zur Version 19.11: [englisch](https://koha-community.org/manual/19.11/en/html/), [deutsch](http://koha-community.org/manual/19.11/de/html/index.html) (noch nicht vollständig übersetzt)
|
||||
* Release Notes zur Version 21.05: <https://koha-community.org/koha-21-05-released/>
|
||||
* Handbuch zur Version 21.05: [englisch](https://koha-community.org/manual/21.05/en/html/), [deutsch](http://koha-community.org/manual/21.05/de/html/index.html) (Übersetzung noch in Arbeit)
|
||||
|
||||
#### Koha Demo
|
||||
|
||||
* MARC21, Koha 19.11 bereitgestellt von schweizer Unternehmen "Admin Kuhn"
|
||||
* [OPAC](http://koha.adminkuhn.ch/)
|
||||
* [Staff Interface](http://koha.adminkuhn.ch:8080/) (Benutzername `demo` / Passwort `demo`)
|
||||
* MARC21, Koha 21.05 bereitgestellt von schweizer Unternehmen "Admin Kuhn" unter http://koha.adminkuhn.ch
|
||||
* Login mit Benutzername `demo` / Passwort `demo` möglich
|
||||
* wird jeweils Morgens um 5 Uhr auf Standardwerte zurückgesetzt
|
||||
* siehe auch die Erläuterungen unter http://adminkuhn.ch/wiki/Koha-Demoinstallation
|
||||
|
||||
### Installation von Koha 19.11
|
||||
### Installation von Koha 21.05
|
||||
|
||||
Die folgenden Befehle orientieren sich an der [offiziellen Installationsanleitung](http://wiki.koha-community.org/wiki/Debian).
|
||||
|
||||
#### Paketquellen für Koha registrieren
|
||||
#### Paketquellen für Koha registrieren
|
||||
|
||||
1. Paketquelle hinzufügen
|
||||
|
||||
```shell
|
||||
echo 'deb http://debian.koha-community.org/koha 21.05 main' | sudo tee /etc/apt/sources.list.d/koha.list
|
||||
```
|
||||
|
||||
2. Schlüssel hinzufügen
|
||||
|
||||
```shell
|
||||
echo 'deb http://debian.koha-community.org/koha 19.11 main' | sudo tee /etc/apt/sources.list.d/koha.list
|
||||
wget -q -O- http://debian.koha-community.org/koha/gpg.asc | sudo apt-key add -
|
||||
```
|
||||
|
||||
3. Paketquellen aktualisieren
|
||||
|
||||
```shell
|
||||
sudo apt-get update
|
||||
```
|
||||
|
||||
#### Koha und die Datenbank MariaDB installieren
|
||||
#### Koha und die Datenbank MariaDB installieren
|
||||
|
||||
```shell
|
||||
sudo apt install koha-common mariadb-server
|
||||
```
|
||||
|
||||
#### Domain `meine-schule.org` für Koha konfigurieren
|
||||
#### Domain `meine-schule.org` für Koha konfigurieren
|
||||
|
||||
```shell
|
||||
sudo sed -i 's/DOMAIN=".myDNSname.org"/DOMAIN=".meine-schule.org"/' /etc/koha/koha-sites.conf
|
||||
```
|
||||
|
||||
#### Apache Konfiguration
|
||||
#### Apache Konfiguration
|
||||
|
||||
```shell
|
||||
sudo a2enmod rewrite
|
||||
sudo a2enmod cgi
|
||||
sudo service apache2 restart
|
||||
sudo a2enmod headers proxy_http
|
||||
sudo systemctl restart apache2
|
||||
```
|
||||
|
||||
#### Eine Bibliothek in Koha erstellen
|
||||
#### Eine Bibliothek in Koha erstellen
|
||||
|
||||
```shell
|
||||
sudo koha-create --create-db bibliothek
|
||||
```
|
||||
|
||||
#### Deutsche Übersetzung für Koha installieren
|
||||
#### Deutsche Übersetzung für Koha installieren
|
||||
|
||||
```shell
|
||||
sudo koha-translate --install de-DE
|
||||
```
|
||||
|
||||
Note:
|
||||
- Fehlermeldung ignorieren:
|
||||
|
||||
> `Connection to the memcached servers '__MEMCACHED_SERVERS__' failed`
|
||||
|
||||
#### "Plack" aktivieren für bessere Performance
|
||||
|
||||
```shell
|
||||
sudo koha-plack --enable bibliothek
|
||||
sudo koha-plack --start bibliothek
|
||||
sudo systemctl restart apache2
|
||||
```
|
||||
|
||||
#### Host-Datei ergänzen
|
||||
|
||||
Es handelt sich um einen einzigen Befehl. Anders als sonst müssen hier also alle vier Zeilen gemeinsam in die Kommandozeile übernommen werden.
|
||||
|
||||
```shell
|
||||
echo '# Koha
|
||||
127.0.0.1 bibliothek.meine-schule.org
|
||||
@ -104,37 +134,73 @@ echo '# Koha
|
||||
' | sudo tee -a /etc/hosts
|
||||
```
|
||||
|
||||
#### Befehl, um generiertes Passwort herauszufinden
|
||||
#### Befehl, um generiertes Passwort herauszufinden
|
||||
|
||||
```shell
|
||||
sudo koha-passwd bibliothek
|
||||
```
|
||||
|
||||
Kopieren Sie das Passwort in die Zwischenablage.
|
||||
|
||||
#### Fertig?
|
||||
|
||||
Wenn die Installation erfolgreich war, dann sollten Sie mit dem Browser auf dem virtuellen Server die Webseite http://bibliothek-intra.meine-schule.org aufrufen können. Dort sollte der Koha-Installationsassistent erscheinen.
|
||||
Wenn die Installation erfolgreich war, dann sollten Sie mit dem Browser auf der virtuellen Maschine die Webseite <http://bibliothek-intra.meine-schule.org> aufrufen können. Dort sollte der Koha-Installationsassistent erscheinen.
|
||||
|
||||
#### Bekanntes Problem
|
||||
|
||||
Aus noch unbekannten Gründen ist manchmal nach erfolgreicher Installation und etwas Wartezeit plötzlich Koha nicht mehr aufrufbar. Dann hilft ein Neustart von Koha:
|
||||
|
||||
```
|
||||
sudo systemctl restart koha-common
|
||||
```
|
||||
|
||||
#### Koha zurücksetzen
|
||||
|
||||
Falls etwas schiefgeht, können Sie die Konfiguration mit den folgenden Befehlen zurücksetzen. Es erscheint dann wieder der Webinstaller und Sie können von Vorne beginnen.
|
||||
|
||||
```shell
|
||||
sudo koha-remove bibliothek
|
||||
sudo koha-create --create-db bibliothek
|
||||
sudo koha-passwd bibliothek
|
||||
```
|
||||
|
||||
Note:
|
||||
- Falls das auch nicht funktioniert, ist vermutlich ein Rest der eingerichteten Bibliothek noch vorhanden. Mit folgenden Befehlen können Sie auch diese Reste löschen. Anschließend sollte das Neuanlegen funktionieren.
|
||||
- `sudo koha-remove --purge-all bibliothek`
|
||||
- `sudo userdel bibliothek-koha`
|
||||
|
||||
### Grundkonfiguration mit Tutorial
|
||||
|
||||
Wir verwenden ein Tutorial von Stephan Tetzel, das auf deutsch und englisch verfügbar ist:
|
||||
|
||||
* Deutsch: <https://zefanjas.de/wie-man-koha-installiert-und-fuer-schulen-einrichtet-teil-1/>
|
||||
* Englisch: <https://openschoolsolutions.org/how-to-install-and-set-up-koha-for-schools-part-1/>
|
||||
* Deutsch: <https://zefanjas.de/wie-man-koha-installiert-und-fuer-schulen-einrichtet-teil-1/>
|
||||
* Englisch: <https://openschoolsolutions.org/how-to-install-and-set-up-koha-for-schools-part-1/>
|
||||
|
||||
**Aufgabe (45 Minuten)**: Bitte bearbeiten Sie das Tutorial, um die Grundkonfiguration von Koha vorzunehmen. Das Tutorial besteht aus 6 Kapiteln (die Links zu den weiteren Kapiteln sind immer am Anfang der Blogartikel):
|
||||
Note:
|
||||
- Da wir eine neuere Koha-Version (21.05) als im Tutorial 20.05 verwenden, gibt es Abweichungen im Detail. Das ist eine Situation, die in der Praxis oft auftritt. Versuchen Sie die Hinweise im Tutorial sinngemäß anzuwenden.
|
||||
|
||||
**Aufgabe**: Bitte bearbeiten Sie das Tutorial, um die Grundkonfiguration von Koha vorzunehmen. Das Tutorial besteht aus 6 Kapiteln (die Links zu den weiteren Kapiteln sind immer am Anfang der Blogartikel):
|
||||
|
||||
1. Installation und Einrichtung einer ersten Bibliothek
|
||||
* Die im Tutorial erwähnte Grundinstallation haben wir oben bereits durchgeführt. Bitte starten Sie in Kapitel 1 unter der Überschrift "Koha einrichten": <https://zefanjas.de/wie-man-koha-installiert-und-fuer-schulen-einrichtet-teil-1/>
|
||||
* Die Grundinstallation haben wir bereits durchgeführt. Starten Sie in [Kapitel 1](https://zefanjas.de/wie-man-koha-installiert-und-fuer-schulen-einrichtet-teil-1/) unter der Überschrift "Koha einrichten".
|
||||
2. Das bibliografische Framework
|
||||
* Hier bitte nur lesen, den Export/Import nicht durchführen.
|
||||
* Dieses Kapitel bitte nur lesen und den Export/Import **nicht** durchführen. Das im Tutorial beschriebene Vorgehen ist fehleranfällig.
|
||||
3. Grundeinstellungen
|
||||
* Mit der Koha-Version 20.05 wurde der Parameter "OpacMainUserBlock" für die Willkommensnachricht von den Systemeinstellungen in das Nachrichten-Werkzeug verschoben (Werkzeuge > Nachrichten > Neuer Eintrag).
|
||||
|
||||
Optional:
|
||||
|
||||
4. Buchaufnahme
|
||||
5. Drucken von Etiketten
|
||||
6. Ausleihkonditionen
|
||||
|
||||
Note:
|
||||
- Koha bietet eine Bearbeitungsfunktion des bibliografischen Frameworks direkt über die Webseite der Admin-Oberfläche (ohne Export/Import). Menüpunkt "MARC-Struktur".
|
||||
- Der Parameter für die Willkommensnachricht wurde von den Systemeinstellungen in das Nachrichten-Werkzeug verschoben. Werkzeuge > Nachrichten > Neuer Eintrag. Anzeigebereich: OpacMainUserBlock
|
||||
|
||||
### Übung: Manuelle Bedienung
|
||||
|
||||
**Aufgabe (15 Minuten)**: Damit Sie ein Gespür für das System erhalten, machen wir nun ein Minimalbeispiel für einen vereinfachten Bibliotheksworkflow:
|
||||
**Aufgabe (20 Minuten)**: Damit Sie ein Gespür für das System erhalten, machen wir nun ein Minimalbeispiel für einen vereinfachten Bibliotheksworkflow:
|
||||
|
||||
1. Buch erfassen
|
||||
2. Benutzer anlegen
|
||||
@ -154,6 +220,18 @@ Start > Katalogisierung > Neuer Titel > Schnellaufnahme
|
||||
* `p - Barcode` muss vergeben werden (sonst können wir später nicht ausleihen)
|
||||
* Unten Button "Exemplar hinzufügen" nicht vergessen
|
||||
|
||||
Note:
|
||||
- Falls bei der Grundinstallation der Import des FA-Frameworks nicht durchgeführt wurde, steht keine Schnellaufnahme zur Verfügung.
|
||||
- Nachinstallation des FA-Frameworks:
|
||||
1. Im Terminal das Framework herunterladen:
|
||||
```bash
|
||||
wget https://raw.githubusercontent.com/sebastian-meyer/bain_fa/master/export_FA.csv
|
||||
```
|
||||
2. In der Koha-Dienstoberfläche: Start -> Administration -> Bibliographisches MARC-Framework
|
||||
3. Button "Neues Framework": Code "FA", Beschreibung "Schnellaufnahme"
|
||||
4. Rechts neben dem neu angelegten Framework über den Pfeil auf "Import"
|
||||
5. Datei "export_FA.csv" auswählen und bestätigen
|
||||
|
||||
#### Benutzer anlegen
|
||||
|
||||
* Start > Benutzer > Benutzer-Schnellerfassung
|
||||
@ -163,30 +241,34 @@ Start > Katalogisierung > Neuer Titel > Schnellaufnahme
|
||||
|
||||
* Oben im Suchschlitz Reiter Ausleihe wählen, Ausweisnummer eingeben und abschicken
|
||||
* Dann in Box "Ausleihe an" den Exemplarbarcode eingeben und Ausleihe abschicken
|
||||
* Über Button "Zeige Ausleihen" prüfen, ob Ausleihe erfolgreich war
|
||||
|
||||
#### Buch an Theke zurücknehmen
|
||||
|
||||
* Oben im Suchschlitz Reiter Rückgabe wählen, Barcode eingeben und abschicken
|
||||
|
||||
### Übung: Datenimport und Export
|
||||
### Übung: Datenimport
|
||||
|
||||
**Aufgabe (15 Minuten)**: Koha verfügt über einige Schnittstellen. Hier ein kleines Beispiel für semi-automatische Erfassung ("copy cataloging"):
|
||||
**Aufgabe (20 Minuten)**: Koha verfügt über einige Schnittstellen. Hier ein kleines Beispiel für semi-automatische Erfassung ("copy cataloging"):
|
||||
|
||||
1. Z39.50 Server einrichten
|
||||
2. "Copy Cataloging"
|
||||
3. Datenexport
|
||||
|
||||
#### Z39.50 Server einrichten
|
||||
#### SRU Server einrichten
|
||||
|
||||
Start > Administration > Z39.50/SRU-Server / Neuer Z39.50-Server
|
||||
Start > Administration > Z39.50/SRU-Server / Neuer SRU-Server
|
||||
|
||||
* Servername: `NEBIS`
|
||||
* Hostname: `opac.nebis.ch`
|
||||
* Port: `9909`
|
||||
* Servername: `GBV`
|
||||
* Hostname: `sru.gbv.de`
|
||||
* Port: `80`
|
||||
* Ausgewählt (Standardsuche): ja
|
||||
* Datenbank: `NEBIS`
|
||||
* Datenbank: `gvk`
|
||||
* Syntax: `MARC21/USMARC`
|
||||
* Codierung: `MARC-8`
|
||||
* Codierung: `utf8`
|
||||
|
||||
Note:
|
||||
- Im Netzwerk der FHGR sind aus Sicherheitsgründen einige Ports gesperrt. Daher können wir mit unserer virtuellen Maschine einige Z39.50 Server wie z.B. von NEBIS auf Port 9909 nicht erreichen.
|
||||
|
||||
#### "Copy Cataloging"
|
||||
|
||||
@ -197,33 +279,101 @@ Start > Katalogisierung > Import über Z39.50/SRU
|
||||
* Im folgenden Katalogisierungsbildschirm können Sie versuchen zu speichern. Es muss aber auf jeden Fall noch der Medientyp in Feld `942c` ausgewählt werden (ein Pflichtfeld).
|
||||
* Im nächsten Bildschirm einen Barcode vergeben und Exemplar hinzufügen.
|
||||
|
||||
#### Datenexport
|
||||
### Exkurs: Datenexport und Schnittstellen
|
||||
|
||||
Start > Werkzeuge > Datenexport
|
||||
* Koha unterstützt dateibasierten Datenexport und diverse Schnittstellen.
|
||||
* Wir nutzen hier die Schnittstelle OAI-PMH.
|
||||
* OAI-PMH steht für [Open Archives Initiative Protocol for Metadata Harvesting](https://www.openarchives.org/pmh/) und ermöglicht regelmäßiges automatisiertes Abrufen von Änderungen.
|
||||
* Im Themenblock "Metadaten modellieren und Schnittstellen nutzen" gehen wir noch genauer darauf ein.
|
||||
|
||||
* Dateiformat: `XML`
|
||||
* Dateiname: `koha.xml`
|
||||
* Download speichern (landet im Ordner `/home/bain/Downloads`)
|
||||
Note:
|
||||
- Vorab: Was nützt OAI-PMH meiner Bibliothek?
|
||||
- Abruf der Daten zur Weiterverarbeitung (z. B. Discovery-System, Digitalisierung)
|
||||
- Erstellung von z. B. Regionalbibliografien oder Themenportalen
|
||||
- Aggregation für Verbundrecherchen
|
||||
- Datenbereitstellung für Digitalisierung, Hackathons, etc.
|
||||
|
||||
### Übung: OAI-PMH
|
||||
|
||||
**Aufgabe (20 Minuten)**: Aktivieren Sie die OAI-PMH-Schnittstelle und prüfen Sie, ob die von Ihnen erstellten Datensätze darüber abrufbar sind
|
||||
|
||||
#### Schnittstelle einrichten
|
||||
|
||||
Start > Administration > Globale Systemparameter > Web Services
|
||||
* OAI-PMH: Aktiviere
|
||||
* OAI-PMH:AutoUpdateSets: Aktiviere
|
||||
* Button "Alle Web Services Parameter speichern"
|
||||
* Siehe auch: <https://koha-community.org/manual/21.05/en/html/administration.html#oai-sets-configuration>
|
||||
|
||||
#### Schnittstelle abfragen
|
||||
|
||||
* Die Basisurl lautet bei uns: <http://bibliothek.meine-schule.org/cgi-bin/koha/oai.pl>
|
||||
* Klicken Sie oben auf die Links "Identify", "Metadata Formats" usw.
|
||||
* Prüfen Sie, ob die von Ihnen erstellten Katalogeinträge abrufbar sind
|
||||
|
||||
### Literatur
|
||||
|
||||
* Koha Anwenderhandbuch des Bibliothekservice-Zentrum Baden-Württemberg: <https://wiki.bsz-bw.de/doku.php?id=l-team:koha:koha-handbuch:start> (für ältere Versionen geschrieben)
|
||||
* Koha Anwenderhandbuch des Bibliothekservice-Zentrum Baden-Württemberg: <https://wiki.bsz-bw.de/display/KOHA/Dokumentation> (für ältere Versionen geschrieben)
|
||||
* Felix Hemme (2016): Katalogisierung mit dem Open-Source-Bibliothekssystem Koha – unter Berücksichtigung des Metadatenstandards MARC 21 und dem Regelwerk RDA. Bachelorarbeit im Studiengang Bibliotheksmanagement der FH Potsdam. <https://nbn-resolving.org/urn:nbn:de:kobv:525-13882>
|
||||
* Implementation Checklist: <https://koha-community.org/manual/19.11/en/html/implementation_checklist.html>
|
||||
* Implementation Checklist: <https://koha-community.org/manual/21.05/en/html/implementation_checklist.html>
|
||||
* Fred King: How to use Koha, MarcEdit, a Raspberry Pi, and a Chicken (optional) to create an ILS for under $100 (September 2019, Vortrag auf Koha-Konferenz): <http://avengingchicken.online/misc/installing_koha_on_raspberry-pi-4.pdf>
|
||||
|
||||
## Cloud-Konzepte am Beispiel von ALMA
|
||||
|
||||
### Verwendung von ALMA an der Fachhochschule Nordwestschweiz (FHNW)
|
||||
|
||||
Notizen zur Live-Demo:
|
||||
|
||||
* Aufbau und Grundlagen: jede SLSP-Bibliothek hat eigene Einstiegsseite in ALMA-Administration
|
||||
* Recherche in Alma / Primo VE: Komplexe Suchoptionen möglich, Anzeige der Treffer ähnlich wie in Discovery-System
|
||||
* Ausleihe und Rückgabe: System verlangt zunächst "Login" an einem Standort, bevor Benutzungsfunktionen angezeigt werden
|
||||
* Benutzerverwaltung: SLSP hat Rollenvorlagen für Mitgliedsbibliotheken erstellt
|
||||
* E-Ressourcen:
|
||||
* Übernahme von Daten aus verschiedenen Schnittstellen möglich. Die meisten Verlage liefern Daten direkt an Ex Libris.
|
||||
* Bestandszeitraum kann "überschrieben" werden
|
||||
* Datenbanken können oft auch im Volltext durchsucht werden.
|
||||
* Konfiguration:
|
||||
* Öffnungszeiten bestimmen den Ablauf der Ausleihfristen. Kann für jede Bibliothek definiert werden.
|
||||
* Die meisten Einstellungen werden an der FHNW auf der Ebene der "Institution Zone" vorgenommen. Beispiel "Briefe" (inkl. E-Mail) zur Nutzerkommunikation
|
||||
* Discovery kann direkt aus ALMA konfiguriert werden. Template (HTML, CSS, JS) kann mit "Primo Studio" erstellt werden. <https://fhnw.swisscovery.slsp.ch>
|
||||
* Benutzerverwaltung: SLSP hat Rollenvorlagen für Mitgliedsbibliotheken erstellt
|
||||
|
||||
### Zusammenspiel Verbund und lokale Änderungen
|
||||
|
||||
> Was passiert, wenn Datensätze in der Community aktualisiert werden, für die lokale "Überschreibungen" vorgenommen wurden?
|
||||
|
||||
Lokale Änderung wird überschrieben und in einer Liste (CZ-Updates - Aufgabenliste) zur Kontrolle notiert
|
||||
|
||||
### Übung: Strategische Spielereien
|
||||
|
||||
Gruppe 1: Argumentation gegenüber Träger / Direktion
|
||||
* Ihr müsst eurer Direktion / dem Träger ein Systemwechsel zu ALMA / SLSP vorschlagen, welche Argumente führt ihr auf?
|
||||
* Wie rechtfertigen wir den sehr viel höheren Mitteleinsatz gegenüber den Trägern und der Direktion?
|
||||
* Seht Ihr Alternativen?
|
||||
|
||||
Gruppe 2: Motivation und Kommunikation der beteiligten Bibliotheken
|
||||
* Wie würdet Ihr die Bibliotheken miteinbeziehen?
|
||||
* Wie würdet Ihr den Change begleiten?
|
||||
* Welche Kommunikationskanäle würdet Ihr nutzen?
|
||||
|
||||
Gruppe 3: Technische Alternativen Pro und Contra
|
||||
* Welche Vor- und Nachteile gibt es bei einem cloudbasierten System?
|
||||
* Gibt es Alternativen zu ALMA / SLSP
|
||||
* Wie beurteilt ihr die Konfigurationsmöglichkeiten?
|
||||
|
||||
## Marktüberblick Bibliothekssysteme
|
||||
|
||||
### Statistiken zum Markt USA/UK
|
||||
|
||||
* Marshall Breeding veröffentlicht jährlich im American Libraries Magazine den "Library Systems Report" und erfasst dafür regelmäßig Statistiken. Daran lässt sich die internationale Entwicklung der Produkte am ehesten ablesen.
|
||||
* [Zusammenfassende Tabellen mit aktuellen Statistiken (2019)](https://americanlibrariesmagazine.org/wp-content/uploads/2019/04/2019-Library-Systems-Report-Tables-UPDATED.pdf)
|
||||
* Vollständiger Bericht: Marshall Breeding (1.5.2019): Library Systems Report 2019. Cycles of innovation. In: American Libraries Magazine. <https://americanlibrariesmagazine.org/2019/05/01/library-systems-report-2019/>
|
||||
* [Zusammenfassende Tabellen mit aktuellen Statistiken (2020)](https://americanlibrariesmagazine.org/wp-content/uploads/2021/04/Library-Systems-Report-2021-Tables-and-Charts.xlsx)
|
||||
* Vollständiger Bericht: Marshall Breeding (3.5.2021): Library Systems Report 2021. Advancing library technologies in challenging times. In: American Libraries Magazine. https://americanlibrariesmagazine.org/2021/05/03/2021-library-systems-report/
|
||||
|
||||
### Aktuelle Entwicklungen
|
||||
|
||||
* Swiss Library Service Platform (SLSP) wird Alma (reines Cloud-Angebot, Server wird in Amsterdam stehen) einführen
|
||||
* Größte Open-Source-Alternative in Entwicklung: [FOLIO](https://www.folio.org)
|
||||
Note:
|
||||
- kurz nach Erscheinen des Berichts wurde ProQuest/ExLibris von Clarivate aufgekauft
|
||||
- Sachliche Einordnung: https://americanlibrariesmagazine.org/blogs/the-scoop/clarivate-to-acquire-proquest/
|
||||
- zugespitzter Kommentar: https://librarianshipwreck.wordpress.com/2021/08/16/mergers-acquisitions-and-my-tinfoil-hat/
|
||||
- Übersicht über vergangene Fusionen und Aufkäufe: https://librarytechnology.org/mergers/
|
||||
|
||||
### Alma im Vergleich zu Aleph und Koha
|
||||
|
||||
@ -231,4 +381,69 @@ Start > Werkzeuge > Datenexport
|
||||
* Siehe dazu Vortrag von Katrin Fischer: [Koha und ERM - Optionen für die Verwaltung von elektronischen Ressourcen](https://nbn-resolving.org/urn:nbn:de:0290-opus4-35840) auf dem Bibliothekartag 2018.
|
||||
* Alma ist auf dem aktuellsten Stand der Technik und bietet vorbildliche Programmierschnittstellen.
|
||||
* Alma ist cloudbasiert, d.h. zentrale Installation auf Servern von Ex Libris und regelmäßige Updates.
|
||||
* Kritiker befürchten langfristig Nachteile durch die Abhängigkeit vom Hersteller Ex Libris und dessen Marktmacht (Vendor-Lock-in).
|
||||
* Kritiker befürchten langfristig Nachteile durch die Abhängigkeit vom Hersteller Ex Libris und dessen Marktmacht (Vendor Lock-in).
|
||||
|
||||
### Wann wird ein ERM-System benötigt?
|
||||
|
||||
* Klassische Bibliothekssysteme können auch einzelne E-Books, digitale Hörbücher etc. verwalten
|
||||
* Manchmal werden Schnittstellen angeboten, um eBooks aus großen Plattformen wie OverDrive zu übernehmen
|
||||
* ERM-Systeme benötigen insbesondere wissenschaftliche Bibliotheken, weil diese "Pakete" von verschiedenen Anbietern erwerben, in denen eine so große Anzahl von elektronischen Zeitschriften und/oder E-Books enthalten ist, dass diese nicht mehr einzeln katalogisiert werden.
|
||||
|
||||
### Unterschiede zwischen wiss. und öff. Bibliothekssoftware
|
||||
|
||||
- Traditionell gibt es große Unterschiede zwischen wissenschaftlichen und öffentlichen Bibliotheken (darunter Schulbibliotheken)
|
||||
- Bibliotheksmanagementsoftware für öffentliche Bibliotheken enthält oft Module für Veranstaltungsmanagement oder Content-Management (Webseiten), legt Schwerpunkte auf optischer Darstellung (Buchcover, Themenschwerpunkte) und bindet Plattformen für E-Books und Hörbücher ein.
|
||||
- Bibliotheksmanagementsoftware für wissenschaftliche Bibliotheken legt Schwerpunkte auf Erschließung, E-Ressourcen-Management (elektronische Zeitschriften) und komplexe Geschäftsgänge
|
||||
|
||||
## Aufgaben
|
||||
|
||||
Bis zum nächsten Termin:
|
||||
|
||||
1. Beitrag im Lerntagebuch zu dieser Lehreinheit (3000 - 4000 Zeichen)
|
||||
2. Installation ArchivesSpace (siehe unten)
|
||||
|
||||
### Installation ArchivesSpace 3.1.0
|
||||
|
||||
1. Java 8 installieren
|
||||
|
||||
```bash
|
||||
sudo apt update
|
||||
sudo apt install openjdk-8-jre-headless
|
||||
```
|
||||
|
||||
2. Zip-Archiv herunterladen und entpacken
|
||||
|
||||
```bash
|
||||
wget https://github.com/archivesspace/archivesspace/releases/download/v3.1.0/archivesspace-v3.1.0.zip
|
||||
unzip -q archivesspace-v3.1.0.zip
|
||||
```
|
||||
|
||||
3. ArchivesSpace starten
|
||||
|
||||
```bash
|
||||
archivesspace/archivesspace.sh
|
||||
```
|
||||
|
||||
Note:
|
||||
- Während Koha in der Standardinstallation so eingerichtet ist, dass es automatisch beim Systemstart zur Verfügung steht, muss ArchivesSpace in der Standardinstallation manuell gestartet werden.
|
||||
- Es ist nur solange verfügbar wie der Prozess im Terminal läuft. Es handelt sich um eine Webanwendung. Im Terminal läuft die Server-Applikation. Über den Browser greifen wir darauf zu. Wenn das Terminal geschlossen wird, dann wird auch der Server beendet und die Webseite im Browser ist nicht mehr erreichbar.
|
||||
|
||||
### ArchivesSpace aufrufen
|
||||
|
||||
Nach ein paar Minuten sollte ArchivesSpace unter folgenden URLs erreichbar sein:
|
||||
|
||||
* http://localhost:8080/ – Administrationsoberfläche / "Staff Interface"
|
||||
* http://localhost:8081/ – Benutzungsoberfläche / "Public Interface"
|
||||
* http://localhost:8082/ – OAI-PMH Schnittstelle
|
||||
|
||||
Zugangsdaten für das "Staff Interface" sind:
|
||||
|
||||
* Username: `admin`
|
||||
* Password: `admin`
|
||||
|
||||
Note:
|
||||
- Die Benutzungsoberfläche ist erst verfügbar, wenn über die Administrationsoberfläche mindestens ein Repository angelegt wurde. (Das machen wir in der nächsten Lehreinheit.)
|
||||
- Da es sich um eine lokale Installation handelt, sind die Adressen nur über den Webbrowser innerhalb der Virtuellen Maschine erreichbar.
|
||||
- Für technisch Interessierte:
|
||||
- Unter http://localhost:8089/ ist die [REST API](https://archivesspace.github.io/archivesspace/api/) erreichbar.
|
||||
- Unter http://localhost:8090/ ist die Suchmaschine Apache Solr erreichbar.
|
||||
|
||||
@ -1,17 +1,12 @@
|
||||
# Funktion und Aufbau von Archivsystemen
|
||||
|
||||
* Metadatenstandards in Archiven (ISAD(G) und EAD) (45 Minuten)
|
||||
* Installation und Konfiguration von ArchivesSpace (125 Minuten)
|
||||
* Marktüberblick Archivsysteme (10 Minuten)
|
||||
* Metadatenstandards in Archiven (ISAD(G) und EAD)
|
||||
* Installation und Konfiguration von ArchivesSpace
|
||||
* Marktüberblick Archivsysteme
|
||||
|
||||
## Metadatenstandards in Archiven (ISAD(G) und EAD)
|
||||
|
||||
1. ISAD(G) (15 Minuten)
|
||||
2. Übung Archivkataloge (20 Minuten)
|
||||
3. EAD (5 Minuten)
|
||||
4. Aktuelle Entwicklungen (5 Minuten)
|
||||
|
||||
### ISAD(G)
|
||||
### Regelwerk: ISAD(G)
|
||||
|
||||
* Als digitale Archivsysteme entwickelt wurden, orientierte sich die Datenstruktur an analogen Findmitteln wie Findbüchern und Zettelkästen.
|
||||
* Ein wichtiger Verzeichnungsstandard im Archivwesen wurde 1994 (Revision 2000) eingeführt, die "International Standard Archival Description (General)" - kurz [ISAD(G)](https://de.wikipedia.org/wiki/ISAD(G)).
|
||||
@ -48,40 +43,40 @@ Von besonderer Bedeutung sind 6 Pflichtfelder:
|
||||
|
||||
#### Normdaten mit ISAD(G)
|
||||
|
||||
* Um Normdateien verzeichnen zu können, wurde später ein ergänzender Standard "International Standard Archival Authority Record for Corporate Bodies, Persons, and Families" - kurz [ISAAR(CPF)](https://de.wikipedia.org/wiki/ISAAR%28CPF%29) verabschiedet. Dieser wird in der Praxis wegen dem Zusatzaufwand bei der Erschließung jedoch nur selten verwendet.
|
||||
* Um Normdateien verzeichnen zu können, wurde später ein ergänzender Standard "International Standard Archival Authority Record for Corporate Bodies, Persons, and Families" - kurz [ISAAR(CPF)](https://de.wikipedia.org/wiki/ISAAR(CPF)) verabschiedet. Dieser wird in der Praxis wegen dem Zusatzaufwand bei der Erschließung jedoch nur selten verwendet.
|
||||
* Aktuell ist ein neuer Standard ["Records in Contexts" (RIC)](https://de.wikipedia.org/wiki/Records_in_Contexts) in Entwicklung. Dieser basiert auf Linked-Data-Prinzipien und soll neue und mehrfache Beziehungen zwischen Entitäten ermöglichen.
|
||||
|
||||
Note:
|
||||
* In den Archiven der ETH-Bibliothek ist wegen der Bibliothekszugehörigkeit die [GND](https://de.wikipedia.org/wiki/Gemeinsame_Normdatei)-ID von besonderer Bedeutung.
|
||||
* Projektgruppe [ENSEMEN](https://vsa-aas.ch/arbeitsgruppen/projektgruppe-ensemen/) arbeitet an einer schweizerischen Ausprägung des neuen Standards [Records in Contexts](https://www.ica.org/en/records-contexts-german) (RiC), mit Beteiligung von Niklaus Stettler (FH Graubünden)
|
||||
- In den Archiven der ETH-Bibliothek ist wegen der Bibliothekszugehörigkeit die [GND](https://de.wikipedia.org/wiki/Gemeinsame_Normdatei)-ID von besonderer Bedeutung.
|
||||
- Projektgruppe [ENSEMEN](https://vsa-aas.ch/arbeitsgruppen/projektgruppe-ensemen/) arbeitet an einer schweizerischen Ausprägung des neuen Standards [Records in Contexts](https://www.ica.org/en/records-contexts-german) (RiC), mit Beteiligung von Niklaus Stettler (FH Graubünden)
|
||||
|
||||
### Übung: Archivkataloge
|
||||
|
||||
**Aufgabe (20 Minuten):**
|
||||
|
||||
* Suchen Sie nach:
|
||||
* `Einstein` im [Online Archivkatalog des Staatsarchivs BS](https://query.staatsarchiv.bs.ch/query/suchinfo.aspx)
|
||||
* `Einstein Ehrat` im [Hochschularchiv ETH Zürich](http://archivdatenbank-online.ethz.ch/)
|
||||
* `Einstein` im [Online Archivkatalog des Staatsarchivs BS](https://query.staatsarchiv.bs.ch/query/suchinfo.aspx)
|
||||
* `Einstein Ehrat` im [Hochschularchiv ETH Zürich](http://archivdatenbank-online.ethz.ch/)
|
||||
* Beantworten Sie die folgenden Fragen:
|
||||
1. Welche Informationen enthält die Trefferliste?
|
||||
2. Welche Verzeichnungsstufen sind vertreten?
|
||||
3. Sind die ISAD(G)-Informationsbereiche erkennbar?
|
||||
4. Decken sich die grundlegenden Informationen oder gibt es bemerkenswerte Unterschiede?
|
||||
5. Worin liegen die zentralen Unterschiede zu einem Bibliothekskatalog?
|
||||
* Zum Nachschlagen: [ISAD(G) Guidelines](https://www.ica.org/sites/default/files/CBPS_2000_Guidelines_ISAD%28G%29_Second-edition_DE.pdf)
|
||||
1. Welche Informationen enthält die Trefferliste?
|
||||
2. Welche Verzeichnungsstufen sind vertreten?
|
||||
3. Sind die ISAD(G)-Informationsbereiche erkennbar?
|
||||
4. Decken sich die grundlegenden Informationen oder gibt es bemerkenswerte Unterschiede?
|
||||
5. Worin liegen die zentralen Unterschiede zu einem Bibliothekskatalog?
|
||||
* Zum Nachschlagen: [ISAD(G) Guidelines](https://www.ica.org/sites/default/files/CBPS_2000_Guidelines_ISAD(G)_Second-edition_DE.pdf)
|
||||
|
||||
### EAD
|
||||
### Datenformat: EAD
|
||||
|
||||
* [Encoded Archival Description](https://de.wikipedia.org/wiki/Encoded_Archival_Description) (EAD) ist ein XML-Standard
|
||||
* Verschiedene Versionen: EAD2002 und EAD3 (August 2015 veröffentlicht)
|
||||
* Verschiedene Versionen: EAD2002 und EAD3 (seit 2015; aktuell ist 1.1.1 von 2019)
|
||||
* Lässt viele Wahlmöglichkeiten offen, daher gibt es oft Anwendungsprofile, die genauer spezifizieren welche Werte zugelassen sind.
|
||||
* Anwendungsfälle: [Archives Portal Europa](https://www.archivesportaleurope.net/de/), [Archivportal-D](https://www.archivportal-d.de), [Kalliope](https://kalliope-verbund.info)
|
||||
* Einführung: [Nicolas Moretto (2014): EAD und digitalisiertes Archivgut](https://wiki.dnb.de/download/attachments/90410326/20140414_KIMWS_EAD.pdf?version=1&modificationDate=1398246420000&api=v2). Präsentation auf dem [DINI AG KIM Workshop 2014](https://wiki.dnb.de/display/DINIAGKIM/KIM+WS+2014) in Mannheim.
|
||||
|
||||
Note:
|
||||
* Wir werden später praktisch mit EAD-Dateien arbeiten, daher hier nur diese Kurzinfo.
|
||||
* Die Präsentationsfolien von Nicolas Moretto geben einen guten Überblick über EAD2002.
|
||||
* Liste der Elemente in EAD2002: https://eadiva.com/2/elements/
|
||||
- Wir werden später praktisch mit EAD-Dateien arbeiten, daher hier nur diese Kurzinfo.
|
||||
- Die Präsentationsfolien von Nicolas Moretto geben einen guten Überblick über EAD2002.
|
||||
- Liste der Elemente [in EAD2002](https://eadiva.com/2/elements/) und [in EAD3](https://eadiva.com/elements/)
|
||||
|
||||
### Aktuelle Entwicklungen
|
||||
|
||||
@ -89,17 +84,12 @@ Note:
|
||||
* Generierung von mehr Volltexten u.a. durch Optical Character Recognition (OCR) auch für Handschriften. Automatisierte Anreicherung von Volltexten durch Named Entity Recognition.
|
||||
* In Wikidata werden Online-Findmittel über Property [Archives at](https://www.wikidata.org/wiki/Property:P485) verzeichnet. Beispiel [Albert Einstein in Wikidata](https://www.wikidata.org/wiki/Q937).
|
||||
* In der Schweiz gibt es eine Vernetzungsinitiative [Metagrid](https://metagrid.ch) und weitere Dienste von [histHub](https://histhub.ch), einer Forschungsplattform für die Historischen Wissenschaften.
|
||||
* Literaturempfehlung: [Umfrage "Was sich Historiker\*innen von Archiven wünschen"](https://dhdhi.hypotheses.org/6107)
|
||||
|
||||
Note:
|
||||
- Literaturempfehlung: [Umfrage "Was sich Historiker*innen von Archiven wünschen"](https://dhdhi.hypotheses.org/6107)
|
||||
|
||||
## Installation und Konfiguration von ArchivesSpace
|
||||
|
||||
1. Einführung in ArchivesSpace (10 Minuten)
|
||||
2. Exkurs zur Systemadministration (5 Minuten)
|
||||
3. Installation ArchivesSpace (30 Minuten)
|
||||
4. Bedienung (45 Minuten)
|
||||
5. Import und Export (30 Minuten)
|
||||
6. Literatur zu ArchivesSpace (5 Minuten)
|
||||
|
||||
### Einführung in ArchivesSpace
|
||||
|
||||
* Open-Source-Software für Archivinformationssysteme
|
||||
@ -110,6 +100,7 @@ Note:
|
||||
#### Funktionen
|
||||
|
||||
"What ASpace does and how do we use it" ([aus Fortbildungsmaterialien der NYU](https://guides.nyu.edu/ld.php?content_id=23461999))
|
||||
|
||||
* System of record for archival materials. Not everything is public, or open to staff, nor is it intended to be.
|
||||
* Perform core archival functions: accessioning, arrangement and description
|
||||
* Aid in public services
|
||||
@ -127,75 +118,33 @@ Note:
|
||||
### Exkurs zur Systemadministration
|
||||
|
||||
Wir haben auf unserem Server bereits Koha installiert. Gibt es Probleme wenn wir ArchivesSpace zusätzlich installieren?
|
||||
|
||||
* Es könnten Versions- oder Ressourcenkonflikte entstehen.
|
||||
* Best Practice: Jedes System in einer eigenen Umgebung.
|
||||
* Koha und ArchivesSpace vertragen sich aber zufällig gut, daher installieren wir hier ArchivesSpace einfach zusätzlich.
|
||||
|
||||
Note:
|
||||
* Es könnte Konflikte geben, wenn die Systeme unterschiedliche Versionen der gleichen Programmiersprache (z.B. Java, PHP) oder der Datenbank (z.B. MySQL, PostgreSQL) benötigen. Es könnten auch die Ressourcen (insbesondere Arbeitsspeicher) knapp werden.
|
||||
* Um den Wartungsaufwand zu reduzieren und Ressourcen zu sparen, werden üblicherwese virtuelle Maschinen oder Container eingesetzt.
|
||||
- Es könnte Konflikte geben, wenn die Systeme unterschiedliche Versionen der gleichen Programmiersprache (z.B. Java, PHP) oder der Datenbank (z.B. MySQL, PostgreSQL) benötigen. Es könnten auch die Ressourcen (insbesondere Arbeitsspeicher) knapp werden.
|
||||
- Um den Wartungsaufwand zu reduzieren und Ressourcen zu sparen, werden üblicherwese virtuelle Maschinen oder Container eingesetzt.
|
||||
|
||||
### Installation ArchivesSpace
|
||||
|
||||
Wir werden nun ArchivesSpace auf den virtuellen Maschinen installieren.
|
||||
|
||||
1. Installation ArchivesSpace 2.7.1
|
||||
2. Staff Interface aufrufen
|
||||
3. Exkurs: Konfigurationsmöglichkeiten
|
||||
4. Grundkonfiguration
|
||||
|
||||
#### Installation ArchivesSpace 2.7.1
|
||||
|
||||
1. Java 8 installieren
|
||||
|
||||
```bash
|
||||
sudo apt update
|
||||
sudo apt install openjdk-8-jre-headless
|
||||
```
|
||||
|
||||
2. Zip-Archiv herunterladen und entpacken
|
||||
|
||||
```bash
|
||||
wget https://github.com/archivesspace/archivesspace/releases/download/v2.7.1/archivesspace-v2.7.1.zip
|
||||
unzip -q archivesspace-v2.7.1.zip
|
||||
```
|
||||
|
||||
3. ArchivesSpace starten
|
||||
|
||||
* Installation war [Aufgabe zur heutigen Sitzung](02_funktion-und-aufbau-von-bibliothekssystemen.md#Aufgaben).
|
||||
* Damit ArchivesSpace verfügbar ist, muss der Prozess im Terminal laufen. Falls zwischenzeitlich geschlossen ggf. noch einmal starten.
|
||||
```bash
|
||||
archivesspace/archivesspace.sh
|
||||
```
|
||||
* Login im Staff Interface unter <http://localhost:8080/>
|
||||
* Username: `admin`
|
||||
* Password: `admin`
|
||||
|
||||
Note:
|
||||
* Während Koha in der Standardinstallation so eingerichtet ist, dass es automatisch beim Systemstart zur Verfügung steht, muss ArchivesSpace in der Standardinstallation manuell gestartet werden.
|
||||
* Es ist nur solange verfügbar wie der Prozess im Terminal läuft. Es handelt sich um eine Webanwendung. Im Terminal läuft die Server-Applikation. Über den Browser greifen wir darauf zu. Wenn das Terminal geschlossen wird, dann wird auch der Server beendet und die Webseite im Browser ist nicht mehr erreichbar.
|
||||
- Während Koha in der Standardinstallation so eingerichtet ist, dass es automatisch beim Systemstart zur Verfügung steht, muss ArchivesSpace in der Standardinstallation manuell gestartet werden.
|
||||
- Es ist nur solange verfügbar wie der Prozess im Terminal läuft. Es handelt sich um eine Webanwendung. Im Terminal läuft die Server-Applikation. Über den Browser greifen wir darauf zu. Wenn das Terminal geschlossen wird, dann wird auch der Server beendet und die Webseite im Browser ist nicht mehr erreichbar.
|
||||
|
||||
#### Staff Interface aufrufen
|
||||
### Grundkonfiguration ArchivesSpace
|
||||
|
||||
Nach ein paar Minuten sollte ArchivesSpace unter folgenden URLs erreichbar sein:
|
||||
|
||||
* http://localhost:8080/ – the staff interface
|
||||
* http://localhost:8081/ – the public interface
|
||||
* http://localhost:8082/ – the OAI-PMH server
|
||||
* http://localhost:8089/ – the backend
|
||||
* http://localhost:8090/ – the Solr admin console
|
||||
|
||||
Zugangsdaten für das "Staff Interface" sind:
|
||||
|
||||
* Username: `admin`
|
||||
* Password: `admin`
|
||||
|
||||
Note:
|
||||
* Da es sich um eine lokale Installation handelt, sind die Adressen nur über den Webbrowser innerhalb der Virtuellen Maschine erreichbar.
|
||||
|
||||
#### Exkurs: Konfigurationsmöglichkeiten
|
||||
|
||||
* Spracheinstellung: Es gibt noch keine deutsche Übersetzung aber Spanisch, Französisch und Japanisch
|
||||
* Konfiguration: <https://archivesspace.github.io/archivesspace/user/configuring-archivesspace/#Language>
|
||||
* Sprachdateien: <https://github.com/archivesspace/archivesspace/tree/master/common/locales>
|
||||
* Weitere Optionen: Siehe technische Dokumentation <https://archivesspace.github.io/archivesspace/user/configuring-archivesspace/>
|
||||
|
||||
#### Grundkonfiguration
|
||||
#### Repository anlegen
|
||||
|
||||
Nach dem ersten Login erscheint die Meldung:
|
||||
|
||||
@ -204,91 +153,113 @@ Nach dem ersten Login erscheint die Meldung:
|
||||
Dort nutzen Sie den Button `Create Repository` um ihr Repository anzulegen.
|
||||
|
||||
* Notwendig sind zunächst nur `Repository Short Name` und `Repository Name`.
|
||||
* Die Checkbox `Publish?` definiert, ob die Daten im "public interface" unter http://localhost:8081 erreichbar sind.
|
||||
* Die Checkbox `Publish?` definiert, ob die Daten im "public interface" unter <http://localhost:8081> erreichbar sind.
|
||||
|
||||
#### Beispiel
|
||||
#### Konfigurationsmöglichkeiten
|
||||
|
||||

|
||||
* Spracheinstellung: Es gibt noch keine deutsche Übersetzung aber Spanisch, Französisch und Japanisch
|
||||
* Konfiguration: <https://archivesspace.github.io/archivesspace/user/configuring-archivesspace/#Language>
|
||||
* Sprachdateien: <https://github.com/archivesspace/archivesspace/tree/master/common/locales>
|
||||
* Weitere Optionen: Siehe technische Dokumentation <https://archivesspace.github.io/archivesspace/user/configuring-archivesspace/>
|
||||
|
||||
### Bedienung
|
||||
|
||||
Wir nutzen nun die zuvor diskutierten Grundlagen und die Erfahrungen aus der Übung zu "Einstein", um Datensätze in ArchivesSpace zu erschließen.
|
||||
* Wir nutzen nun die zuvor diskutierten Grundlagen, um Datensätze in ArchivesSpace zu erschließen.
|
||||
* Versuchen Sie bei der folgenden Gruppenarbeit intuitiv vorzugehen und tauschen Sie sich untereinander aus.
|
||||
* Denken Sie an das Provenienzprinzip. Jede Ressource, die Sie verzeichnen wollen, benötigt zunächst Informationen zur Herkunft (Akzession).
|
||||
|
||||
Versuchen Sie bei der folgenden Gruppenarbeit intuitiv vorzugehen und tauschen Sie sich untereinander aus.
|
||||
#### Begrifflichkeiten
|
||||
|
||||
* [Accession](https://docs.google.com/document/d/11kWxbFTazB6q5fDNBWDHJxMf3wdVsp8cd7HzjEhE-ao/edit#heading=h.qp2gyscl8fra): Dokumentation der Erwerbung, wegen vertraulichen Angaben oft nicht öffentlich
|
||||
* [Resource](https://docs.google.com/document/d/11kWxbFTazB6q5fDNBWDHJxMf3wdVsp8cd7HzjEhE-ao/edit#heading=h.jvn83ztmj4y4): Zentraler Nachweis auf der obersten Ebene der Verzeichnungsstufen, zum Beispiel zu einem Nachlass (kann aber auch direkt zum Objekt sein, wenn die Resource nur eine Verzeichnungsstufe hat)
|
||||
* [Archival Object](https://docs.google.com/document/d/11kWxbFTazB6q5fDNBWDHJxMf3wdVsp8cd7HzjEhE-ao/edit#heading=h.nscr859g1snm): Nachweis von Objekten auf weiteren Verzeichnungsstufen (Bestand/Fonds, Serie/Series, Akte/File, Einzelstück/Item). Sie werden über "Add Child" an vorhandene Resources gehängt.
|
||||
|
||||
Note:
|
||||
- Verlinkte Begriffe führen zum [ArchivesSpace Manual for Local Usage at NYU](https://docs.google.com/document/d/11kWxbFTazB6q5fDNBWDHJxMf3wdVsp8cd7HzjEhE-ao/edit), weil das offizielle Handbuch nur für Mitglieder zugänglich ist.
|
||||
|
||||
#### Übung: Datensätze erstellen
|
||||
|
||||
**Aufgabe (40 Minuten)**
|
||||
|
||||
* Aufgabe: Erstellen Sie eigene Datensätze in Ihrer ArchivesSpace Installation. Erfinden Sie dazu sinnvolle Archivdaten oder suchen Sie sich Beispieldaten (z.B. im [Hochschularchiv der ETH](http://archivdatenbank-online.ethz.ch)).
|
||||
* Ziel: Ihre Datensätze erscheinen in der öffentlichen Ansicht unter http://localhost:8081. Machen Sie einen Screenshot und laden Sie das Bild hier in das gemeinsame Dokument.
|
||||
* Ziel: Ihre Datensätze erscheinen in der öffentlichen Ansicht unter <http://localhost:8081>. Machen Sie einen Screenshot und laden Sie das Bild hier in das gemeinsame Dokument.
|
||||
* Hinweis: Orientieren Sie sich beim Vorgehen an der Übung der NYU: [Create Your Own Record](https://guides.nyu.edu/ld.php?content_id=23198351)
|
||||
|
||||
### Literatur zu ArchivesSpace
|
||||
|
||||
* Einführungsvideos: <https://www.youtube.com/playlist?list=PL3cxupmXL7WiXaHnpVquPrUUiLiDAMhg0>
|
||||
* ArchivesSpace Wiki: <https://archivesspace.atlassian.net/wiki/spaces/ADC/>
|
||||
* ArchivesSpace Manual for Local Usage at NYU: <https://docs.google.com/document/d/11kWxbFTazB6q5fDNBWDHJxMf3wdVsp8cd7HzjEhE-ao/edit>
|
||||
Note:
|
||||
- Das Benutzerhandbuch von ArchivesSpace steht nur zahlenden Mitgliedern zur Verfügung. Bei Open-Source-Software suchen die Communities oft nach einem Zusatzvorteil für Mitglieder, weil die Software selbst ja kostenfrei erhältlich ist. Wirklich "open" ist diese Zurückhaltung von Informationen nicht so recht.
|
||||
|
||||
## Marktüberblick Archivsysteme
|
||||
|
||||
* ArchivesSpace hat eine große Community in den USA
|
||||
* Weitere Open-Source-Alternative: [Access to Memory (AtoM)](https://www.accesstomemory.org)
|
||||
* Dienstleister in der Schweiz: [docuteam](https://www.docuteam.ch/atom-access-to-memory/)
|
||||
* Der Markt in der Schweiz wird von den Produkten [scopeArchiv](https://www.scope.ch/de/produkteuebersicht/scopearchiv/) und [CMI AIS](https://cmiag.ch/akten-management/archivierung/ais/) (ehemals CMISTAR) dominiert.
|
||||
* Für die Online-Präsentation von digitalisiertem Archivgut wird oft zusätzliche Software eingesetzt. Beispiele:
|
||||
* [E-Pics Plattform der ETH Zürich](https://www.e-pics.ethz.ch) (WordPress + Canto Cumulus)
|
||||
* [e-manuscripta.ch - Kooperative Präsentationsplattorm für handschriftliche Quellen](http://www.e-manuscripta.ch) (Visual Library)
|
||||
|
||||
Note:
|
||||
- In den Archiven der ETH-Bibliothek wird CMISTAR verwendet. Im "Rich-Client" (Programm für die Mitarbeiter*innen) wird die Erschließung anhand der ISAD(G) Informationsbereiche kategorisiert. CMISTAR beinhaltet auch ein grafisches Mapping-Tool für den Import von Excel oder CSV. Das wird verwendet, um Eingaben von Hilfskräften in Excel in das System zu importieren.
|
||||
|
||||
### Unterschiede zwischen Bibliotheks- und Archivsystemen
|
||||
|
||||
* Bibliothek
|
||||
* (Massen-)Medium, Benutzerinteraktion (Ausleihe)
|
||||
* Software medienzentriert
|
||||
* Metadatenformat: MARC21, zukünftig BIBFRAME?
|
||||
* Archiv
|
||||
* Entstehungszusammenhang, eher stehender, unikaler Bestand (Nutzung auf Anfrage)
|
||||
* Software orientiert sich an analogen Findmitteln
|
||||
* Metadatenformat: EAD, zukünftig RiC
|
||||
|
||||
Note:
|
||||
- Herausforderung: Datenaustausch zwischen den Systemen (kommen wir später darauf zurück)
|
||||
|
||||
## Aufgaben
|
||||
|
||||
Bis zum nächsten Termin:
|
||||
|
||||
1. Beitrag im Lerntagebuch zu dieser Lehreinheit (3000 - 4000 Zeichen).
|
||||
2. Datensätze in ArchivesSpace vervollständigen. Mindestens Accession und Resource. Beides sollte unter <http://localhost:8081> (öffentliche Ansicht) erscheinen.
|
||||
3. Übung zu Import und Export (siehe unten) und dazu einen Beitrag im Lerntagebuch verfassen (1000-2000 Zeichen).
|
||||
|
||||
### Import und Export
|
||||
|
||||
ArchivesSpace bietet dateibasierten Import und Export in diversen Formaten (EAD, MARCXML, CSV) und auch eine OAI-PMH-Schnittstelle (diese lernen wir später noch kennen).
|
||||
ArchivesSpace bietet dateibasierten Import und Export in diversen Formaten (EAD, MARCXML, CSV) und auch eine OAI-PMH-Schnittstelle.
|
||||
|
||||
In den folgenden zwei Übungen werden wir die vorhin selbst erstellten Daten in MARCXML exportieren und EAD-Beispieldaten in ArchivesSpace importieren.
|
||||
|
||||
#### Übung: Export
|
||||
|
||||
**Aufgabe (10 Minuten)**
|
||||
|
||||
* Aufgabe: Exportieren Sie die von Ihnen eingegebenen Datensätze im Format MARCXML. Vergleichen Sie die exportierte XML-Datei kurz mit den in ArchivesSpace vorhandenen Informationen. Ist der Export in MARCXML verlustfrei?
|
||||
* Ziel: Dokumentieren Sie Ihre Erkenntnisse unten im gemeinsamen Dokument.
|
||||
* Hinweis: Die Export-Funktion finden Sie etwas versteckt in der Button-Leiste bei einzelnen Datensätzen.
|
||||
|
||||
Note:
|
||||
* Mappingtabellen als XLS (Stand 2013, unklar ob aktuell) stellt ArchivesSpace auf der Webseite zur Verfügung: <https://archivesspace.org/using-archivesspace/migration-tools-and-data-mapping>
|
||||
* Technische Dokumentation der Konvertierung in MARCXML (falls jemand die Proogrammiersprache Ruby können sollte): https://archivesspace.github.io/archivesspace/doc/MarcXMLConverter.html
|
||||
In den folgenden zwei Übungen werden wir EAD-Beispieldaten in ArchivesSpace importieren und anschließend in MARCXML exportieren.
|
||||
|
||||
#### Übung: Import
|
||||
|
||||
**Aufgabe (15 Minuten)**
|
||||
|
||||
* Beispieldaten: https://eadiva.com/2/sample-ead2002-files/ (laden Sie eine der als "a raw XML file" verlinkten Dateien herunter)
|
||||
* Aufgabe: Importieren Sie Beispieldaten im Format EAD in ArchivesSpace. Vergleichen Sie die Anzeige in ArchivesSpace mit der bei den Beispieldaten verlinkten HTML-Ansicht.
|
||||
* Ziel: Dokumentieren Sie Ihre Erkenntnisse unten im gemeinsamen Dokument.
|
||||
* Beispieldaten: <https://eadiva.com/sample-ead-files/> (laden Sie die als "a raw XML file" verlinkte Datei der "American Association of Industrial Editors" herunter)
|
||||
* Aufgabe: Importieren Sie Beispieldaten im Format EAD in ArchivesSpace. Vergleichen Sie (ganz grob) die Anzeige in ArchivesSpace mit der bei den Beispieldaten verlinkten HTML-Ansicht.
|
||||
* Ziel: Dokumentieren Sie Ihre Erkenntnisse ~~unten im gemeinsamen Dokument.~~ in Ihrem Lerntagebuch.
|
||||
* Hinweis: Die Import-Funktion finden Sie etwas versteckt unter `Create` > `Background Job` > `Import Data`
|
||||
|
||||
Note:
|
||||
* Import kann etwas länger dauern weil,
|
||||
* wir nur die mitgelieferte Datenbank (für Testzwecke) verwendet haben und keine separate MySQL-Datenbank
|
||||
* EAD ein komplexes Dateiformat ist, was etwas aufwendiger auszuwerten ist (daher auch die mehreren "Cycles" in der Log-Datei)
|
||||
* ArchivesSpace in der Grundeinstellung nur 1 GB RAM benutzt, siehe Dokumentation zu "Tuning": <http://archivesspace.github.io/archivesspace/user/tuning-archivesspace/>
|
||||
|
||||
### Literatur zu ArchivesSpace
|
||||
- Import kann etwas länger dauern weil,
|
||||
- wir nur die mitgelieferte Datenbank (für Testzwecke) verwendet haben und keine separate MySQL-Datenbank
|
||||
- EAD ein komplexes Dateiformat ist, was etwas aufwendiger auszuwerten ist (daher auch die mehreren "Cycles" in der Log-Datei)
|
||||
- ArchivesSpace in der Grundeinstellung nur 1 GB RAM benutzt, siehe Dokumentation zu "Tuning": https://archivesspace.github.io/tech-docs/provisioning/tuning.html
|
||||
|
||||
* Einführungsvideos: https://www.youtube.com/playlist?list=PL3cxupmXL7WiXaHnpVquPrUUiLiDAMhg0
|
||||
* ArchivesSpace Wiki: https://archivesspace.atlassian.net/wiki/spaces/ADC/
|
||||
* ArchivesSpace Manual for Local Usage at NYU: https://docs.google.com/document/d/11kWxbFTazB6q5fDNBWDHJxMf3wdVsp8cd7HzjEhE-ao/edit#
|
||||
* Workflow Overview bei Orbis Cascade Alliance (ArchivesSpace 1.5.2): https://www.orbiscascade.org/achivesspace-workflow-overview/
|
||||
#### Übung: Export
|
||||
|
||||
**Aufgabe (15 Minuten)**
|
||||
|
||||
* Aufgabe:
|
||||
1. Exportieren Sie die von Ihnen zuvor importierten Datensätze im Format MARCXML. Speichern Sie die Datei auf der Festplatte.
|
||||
2. Vergleichen Sie die exportierte MARCXML-Datei kurz mit den in ArchivesSpace vorhandenen Informationen. Ist der Export in MARCXML verlustfrei?
|
||||
* Ziel: Dokumentieren Sie Ihre Erkenntnisse unten im gemeinsamen Dokument.
|
||||
* Hinweis: Die Export-Funktion finden Sie etwas versteckt in der Button-Leiste bei der "Resource".
|
||||
|
||||
Note:
|
||||
* Das Benutzerhandbuch von ArchivesSpace steht nur zahlenden Mitgliedern zur Verfügung. Bei Open-Source-Software suchen die Communities oft nach einem Zusatzvorteil für Mitglieder, weil die Software selbst ja kostenfrei erhältlich ist. Wirklich "open" ist diese Zurückhaltung von Informationen nicht so recht.
|
||||
|
||||
## Marktüberblick Archivsysteme
|
||||
|
||||
* ArchivesSpace hat eine große Community in den USA
|
||||
* Weitere Open-Source-Alternative: [Access to Memory (Atom)](https://www.accesstomemory.org)
|
||||
* Der Markt in der Schweiz wird von den Produkten [scope.Archiv](http://www.scope.ch) und [CMISTAR](https://www.cmiag.ch/cmistar) dominiert.
|
||||
* Für die Online-Präsentation von digitalisiertem Archivgut wird oft zusätzliche Software eingesetzt. Beispiele:
|
||||
* [E-Pics Plattform der ETH Zürich](https://www.e-pics.ethz.ch)
|
||||
* [e-manuscripta.ch - Kooperative Präsentationsplattorm für handschriftliche Quellen](http://www.e-manuscripta.ch)
|
||||
|
||||
Note:
|
||||
* In den Archiven der ETH-Bibliothek wird CMI STAR verwendet. Im "Rich-Client" (Programm für die Mitarbeiter\*innen) wird die Erschließung anhand der ISAD(G) Informationsbereiche kategorisiert. CMI STAR beinhaltet auch ein grafisches Mapping-Tool für den Import von Excel oder CSV. Das wird verwendet, um Eingaben von Hilfskräften in Excel in das System zu importieren.
|
||||
|
||||
### Unterschiede zwischen Bibliotheks- und Archivsystemen
|
||||
|
||||
* Bibliothek
|
||||
* Medium, Benutzerinteraktion (Ausleihe)
|
||||
* Software medienzentriert
|
||||
* Metadatenformat: MARC21, zukünftig BIBFRAME?
|
||||
* Archiv
|
||||
* Entstehungszusammenhang, eher stehender Bestand (auf Anfrage)
|
||||
* Software orientiert sich an analogen Findmitteln
|
||||
* Metadatenformat: EAD, zukünftig RiC
|
||||
|
||||
Note:
|
||||
* Herausforderung: Datenaustausch zwischen den Systemen (kommen wir später darauf zurück)
|
||||
- Mappingtabellen als XLS (Stand 2013, unklar ob aktuell) stellt ArchivesSpace auf der Webseite zur Verfügung: <https://archivesspace.org/using-archivesspace/migration-tools-and-data-mapping>
|
||||
- Technische Dokumentation der Konvertierung in MARCXML (falls jemand die Proogrammiersprache Ruby können sollte): <https://archivesspace.github.io/archivesspace/doc/MarcXMLConverter.html>
|
||||
|
||||
@ -1,8 +1,8 @@
|
||||
# Repository-Software für Publikationen und Forschungsdaten
|
||||
|
||||
* Open Access und Open Data (15 Minuten)
|
||||
* Installation und Konfiguration von DSpace (70 Minuten)
|
||||
* Marktüberblick Repository-Software (10 Minuten)
|
||||
* Open Access und Open Data
|
||||
* Übungen mit DSpace
|
||||
* Marktüberblick Repository-Software
|
||||
|
||||
## Open Access und Open Data
|
||||
|
||||
@ -15,6 +15,9 @@
|
||||
* [Verzeichnis von Forschungsdaten-Repositorien](https://www.re3data.org)
|
||||
* Fokus: Primärdaten, die bei der Forschung entstehen. Oft Daten als Anhang zu Zeitschriftenartikeln.
|
||||
|
||||
Note:
|
||||
- Unterscheidung institutionelles Repositorium vs. Fachrepositorium
|
||||
|
||||
### Forschungsinformationen
|
||||
|
||||
* Informationen über Forschende, Drittmittelprojekte, Patente und vieles mehr.
|
||||
@ -27,22 +30,15 @@
|
||||
* [Zenodo](https://zenodo.org) (Invenio)
|
||||
* [TUHH Open Research](https://tore.tuhh.de) (DSpace-CRIS)
|
||||
|
||||
## Installation und Konfiguration von DSpace
|
||||
|
||||
1. Einführung in DSpace (5 Minuten)
|
||||
2. DSpace Demo (5 Minuten)
|
||||
3. Übung: Communities und Collections (30 Minuten)
|
||||
4. Übung: Einreichung und Review (20 Minuten)
|
||||
5. Import und Export (5 Minuten)
|
||||
6. Literatur zu DSpace (5 Minuten)
|
||||
## Übungen mit DSpace
|
||||
|
||||
### Einführung in DSpace
|
||||
|
||||
* Software geeignet für Publikationen und Forschungsdaten
|
||||
* Erweiterung für Forschungsinformationen: DSpace-CRIS.
|
||||
* Metadatenstandard: Qualified Dublin Core, kann aber auch mit [DataCite](https://schema.datacite.org/) Metadatenschema betrieben werden.
|
||||
* DSpace 6.x: 2016 erstmalig veröffentlicht, wird gepflegt, aber nicht mehr weiterentwickelt.
|
||||
* DSpace 7.x: Veröffentlichung in 2020 geplant, neue Technologien im Frontend (Angular) und Backend (neue REST API).
|
||||
* DSpace 6.x: 2016 erstmalig veröffentlicht (aktuell 6.3), wird gepflegt, aber nicht mehr weiterentwickelt.
|
||||
* DSpace 7.x: im August 2021 veröffentlicht (aktuell 7.1), neue Technologien im Frontend (Angular) und Backend (neue REST API), aber noch nicht voller Funktionsumfang von 6.x.
|
||||
|
||||
### DSpace Demo
|
||||
|
||||
@ -50,57 +46,69 @@ Aus Zeitgründen keine Installation, nur Test mit öffentlich zugänglicher Demo
|
||||
|
||||
DSpace 6.x Demo: <https://demo.dspace.org>
|
||||
|
||||
* Site Administrator: `dspacedemo+admin@gmail.com`
|
||||
* Community Administrator: `dspacedemo+commadmin@gmail.com`
|
||||
* Collection Administrator: `dspacedemo+colladmin@gmail.com`
|
||||
* Submitter: `dspacedemo+submit@gmail.com`
|
||||
* Passwort immer: `dspace`
|
||||
- Site Administrator: `dspacedemo+admin@gmail.com`
|
||||
- Community Administrator: `dspacedemo+commadmin@gmail.com`
|
||||
- Collection Administrator: `dspacedemo+colladmin@gmail.com`
|
||||
- Submitter: `dspacedemo+submit@gmail.com`
|
||||
- Passwort immer: `dspace`
|
||||
|
||||
Note:
|
||||
* Sie können die XMLUI oder die JSPUI verwenden. Beide Oberflächen sind mit dem gleichen Backend verbunden.
|
||||
- Sie können die XMLUI oder die JSPUI verwenden. Beide Oberflächen sind mit dem gleichen Backend verbunden.
|
||||
|
||||
### Übung: Communities und Collections
|
||||
|
||||
**Aufgabe (30 Minuten)**
|
||||
**Aufgabe (10 Minuten)**
|
||||
|
||||
* Aufgabe: Melden Sich mit dem Account "Site Administrator" in der DSpace demo an. Erstellen Sie dann eine Community und legen Sie darin eine Collection an.
|
||||
* Ziel: Dokumentieren Sie den Link zur Collection unten im gemeinsamen Dokument.
|
||||
* Hinweis: [Erläuterungen in der How-To von DSpaceDirect](https://wiki.lyrasis.org/display/DSpaceDirectKB/Getting+Started+How-To#GettingStartedHowTo-Communities&Collections)
|
||||
* Aufgabe: Erstellen Sie eine Sub-Community der "Sample Community" und legen Sie darin eine Collection an.
|
||||
* Login: `dspacedemo+commadmin@gmail.com`
|
||||
* Passwort: `dspace`
|
||||
* Sample Community [in XML UI](https://demo.dspace.org/xmlui/handle/10673/1) und [in JSP UI](https://demo.dspace.org/jspui/handle/10673/1)
|
||||
* Ziel: Dokumentieren Sie den Link zu Ihrer Collection unten im gemeinsamen Dokument.
|
||||
* Hinweise:
|
||||
* Weisen Sie Rechte für den Account "Collection Administrator" zu
|
||||
* [Erläuterungen in der How-To von DSpaceDirect](https://wiki.lyrasis.org/display/DSpaceDirectKB/Getting+Started+How-To#GettingStartedHowTo-Communities&Collections)
|
||||
|
||||
Note:
|
||||
- Der Grund, warum es zusätzlich zu Collections auch noch Communities gibt, ist das Rechtemanagement. In der Community wird festgelegt wer die (ggf. mehrere zugehörige) Collections verwalten darf. Das möchte man nur an einer Stelle und nicht an jeder Collection definieren. Außerdem können ganze Communities "geharvestet" werden, also Daten einer Einrichtung über die Schnittstellen abgefragt werden.
|
||||
|
||||
### Übung: Einreichung und Review
|
||||
|
||||
**Aufgabe (20 Minuten)**
|
||||
|
||||
* Aufgabe: Reichen Sie ein Beispieldokument für Ihre Collection ein. Starten Sie falls nötig den Begutachtungsprozess (falls beim Anlegen der Collection aktiviert) und veröffentlichen Sie das Dokument.
|
||||
* Ziel: Dokumentieren Sie den Link zur Veröffentlichung unten im gemeinsamen Dokument.
|
||||
* Login: `dspacedemo+colladmin@gmail.com`
|
||||
* Passwort: `dspace`
|
||||
* Ziel: Dokumentieren Sie den Link zu Ihrer Veröffentlichung unten im gemeinsamen Dokument.
|
||||
* Hinweis: [Erläuterungen in der How-To von DSpaceDirect](https://wiki.lyrasis.org/display/DSpaceDirectKB/Getting+Started+How-To#GettingStartedHowTo-Adding/SubmittingItems).
|
||||
|
||||
Note:
|
||||
* Der Einreichungs- und Begutachtungsprozess in DSpace ist sehr umfangreich konfigurierbar. Alle Formulare können angepasst und vereinfacht werden.
|
||||
* Der Hinweis von DSpaceDirect, dass das Geld kostet, bezieht sich auf deren Hosting. Wenn Sie DSpace selbst hosten, können Sie natürlich alles selbst kostenfrei konfigurieren.
|
||||
* Automatische Datenübernahme via DOIs kann auch angeboten werden, so dass nicht alle Daten manuell eingegeben werden müssen.
|
||||
- Der Einreichungs- und Begutachtungsprozess in DSpace ist sehr umfangreich konfigurierbar. Alle Formulare können angepasst und vereinfacht werden.
|
||||
- Der Hinweis von DSpaceDirect, dass das Geld kostet, bezieht sich auf deren Hosting. Wenn Sie DSpace selbst hosten, können Sie natürlich alles selbst kostenfrei konfigurieren.
|
||||
- Automatische Datenübernahme via DOIs kann auch angeboten werden, so dass nicht alle Daten manuell eingegeben werden müssen.
|
||||
|
||||
### Import und Export
|
||||
|
||||
DSpace bietet auch dateibasierten Import, besonders relevant sind im Kontext von Repositorien aber die Schnittstellen:
|
||||
* SWORD ermöglicht den Import aus anderen Systemen.
|
||||
* OAI-PMH ermöglicht es externen Systemen die in DSpace verzeichneten Metadaten abzurufen.
|
||||
* DSpace bietet auch dateibasierten Import, besonders relevant sind im Kontext von Repositorien aber die Schnittstellen:
|
||||
* SWORD ermöglicht die Publikation in DSpace auf anderen Webseiten.
|
||||
* OAI-PMH ermöglicht es externen Systemen die in DSpace verzeichneten Metadaten abzurufen.
|
||||
* OAI-PMH-Schnittstelle der DSpace-Demo (Daten erscheinen dort zeitverzögert): <http://demo.dspace.org/oai/request?verb=ListSets>
|
||||
* Beispiel für Portal auf Basis von OAI-PMH: Die [Bielefeld Academic Search Engine (BASE)](https://www.base-search.net/) "erntet" weltweit OAI-PMH-Schnittstellen und verzeichnet damit weit über 250 Mio. Dokumente.
|
||||
|
||||
OAI-PMH-Schnittstelle der DSpace-Demo (Daten erscheinen dort zeitverzögert): <http://demo.dspace.org/oai/request?verb=ListSets>
|
||||
|
||||
Beispiel für Portal auf Basis von OAI-PMH: Die [Bielefeld Academic Search Engine (BASE)](base-search.net) "erntet" weltweit OAI-PMH-Schnittstellen und verzeichnet damit weit über 100 Mio. Dokumente.
|
||||
Note:
|
||||
- [SWORD](https://en.wikipedia.org/wiki/SWORD_(protocol)) ist eine Schnittstelle, um Publikationen in einem Repository abzuliefern. Damit kann ein Formular mit Dateiupload auf einer Webseite (außerhalb der Repository-Webseite) angeboten werden.
|
||||
- Um Daten aus dem Repository auf Webseiten anzuzeigen, z.B. eine Publikationsliste, werden andere Schnittstellen wie [RSS-Feeds](https://de.wikipedia.org/wiki/RSS_(Web-Feed)) verwendet.
|
||||
|
||||
### Literatur zu DSpace
|
||||
|
||||
* Videomitschnitte der Präsentationen auf dem D/A/CH-Anwendertreffen 2020: <https://wiki.lyrasis.org/display/DSPACE/DSpace-Anwendertreffen+2020>
|
||||
* Videomitschnitte der Präsentationen auf den jährlichen D/A/CH-Anwendertreffen: https://wiki.lyrasis.org/display/DSPACE/DSpace+Anwendertreffen+2021
|
||||
* Weitere Demo-Installationen:
|
||||
* DSpace 5.x mit DSpace-CRIS: <https://dspace-cris.4science.it/> (nur lesend)
|
||||
* DSpace 7.x: <https://dspace7-demo.atmire.com> (nur lesend)
|
||||
* Suchmaschinenoptimierung (SEO): [Abschnitt im Nutzerhandbuch von DSpace zu SEO](https://wiki.lyrasis.org/display/DSDOC5x/Search+Engine+Optimization)
|
||||
* DSpace 7.x: https://demo7.dspace.org/home (Zugangsdaten wie oben)
|
||||
* DSpace 7.x mit DSpace-CRIS: https://dspacecris7.4science.cloud (nur lesend)
|
||||
* Suchmaschinenoptimierung (SEO): [Abschnitt im Nutzerhandbuch von DSpace zu SEO](https://wiki.lyrasis.org/display/DSDOC7x/Search+Engine+Optimization)
|
||||
|
||||
## Marktüberblick Repository-Software
|
||||
|
||||
* Grundsätzliches zu Repositorien: <https://open-access.net/informationen-zu-open-access/repositorien>
|
||||
* Grundsätzliches zu Repositorien: <https://open-access.network/informieren/open-access-grundlagen/repositorien>
|
||||
* Open Directory of Open Access Repositories (OpenDOAR)
|
||||
* [Weltweit](https://v2.sherpa.ac.uk/view/repository_visualisations/1.html)
|
||||
* [Schweiz](https://v2.sherpa.ac.uk/view/repository_by_country/Switzerland.default.html)
|
||||
@ -113,11 +121,18 @@ Alle Open Source!
|
||||
* [DSpace](https://www.dspace.org)
|
||||
* [EPrints](https://www.eprints.org)
|
||||
* [Fedora](http://fedorarepository.org) / [Islandora](https://islandora.ca)
|
||||
* [Invenio](https://invenio-software.org)
|
||||
* [InvenioRDM](https://invenio-software.org/products/rdm/)
|
||||
* [MyCoRe](https://www.mycore.de)
|
||||
* [OPUS](https://www.opus-repository.org)
|
||||
|
||||
Note:
|
||||
* Invenio arbeitet an interessanten neuen Lösungen:
|
||||
* [InvenioRDM](https://invenio-software.org/products/rdm/) - "The turn-key research data management repository. Launching in the summer 2020"
|
||||
* [InvenioILS](https://invenio-software.org/products/ils/) - "Modern Integrated Library System. Coming soon - beginning of 2020"
|
||||
## Aufgaben
|
||||
|
||||
Bis zum nächsten Termin:
|
||||
|
||||
1. Beitrag im Lerntagebuch zu dieser Lehreinheit (3000 - 4000 Zeichen)
|
||||
2. Übung zur OAI-PMH-Schnittstelle und dazu einen Beitrag im Lerntagebuch verfassen (1000-2000 Zeichen)
|
||||
* Laden Sie von Ihnen erstellte Daten in der DSpace-Demo über die OAI-PMH-Schnittstelle (Daten erscheinen dort zeitverzögert ca. 1 Tag)
|
||||
* Achtung: Daten auf [demo.dspace.org](http://demo.dspace.org) werden jeden Samstag nachts gelöscht.
|
||||
* Rufen Sie bei einer von Ihnen erstellten Community unter http://demo.dspace.org/oai/request?verb=ListSets den Link "Records" auf
|
||||
* Sie finden die Daten jeweils im Kasten "Metadata".
|
||||
* Kopieren Sie die Inhalte in einen Texteditor und spei chern Sie diese auf der Festplatte der virtuellen Maschine (z.B. im Ordner "Downloads")
|
||||
|
||||
@ -1,144 +1,690 @@
|
||||
# Metadaten modellieren und Schnittstellen nutzen
|
||||
|
||||
1. Transformation von Metadaten mit OpenRefine (15 Minuten)
|
||||
2. XSLT Crosswalks mit MarcEdit (25 Minuten)
|
||||
3. Austauschprotokolle für Metadaten (OAI-PMH, SRU) (45 Minuten)
|
||||
4. Weitere Tools zur Metadatentransformation (10 Minuten)
|
||||
5. Nutzung von JSON-APIs (20 Minuten)
|
||||
* Zwischenstand (Schaubild)
|
||||
* Auswertung der Übung zu DSpace
|
||||
* Austauschprotokolle für Metadaten (OAI-PMH, SRU)
|
||||
* Metadaten über OAI-PMH harvesten mit VuFindHarvest
|
||||
* XSLT Crosswalks mit MarcEdit
|
||||
* Transformation von Metadaten mit OpenRefine
|
||||
* Weitere Tools zur Metadatentransformation
|
||||
* Nutzung von JSON-APIs
|
||||
|
||||
## Zwischenstand (Schaubild)
|
||||
|
||||

|
||||
|
||||
Note:
|
||||
- Wir haben die Demo von DSpace getestet und in der Übung Daten aus DSpace über die OAI-PMH-Schnittstelle abgerufen.
|
||||
- Nun wollen wir auch die OAI-PMH-Schnittstellen von unseren lokal installierten Systemen Koha und ArchivesSpace abrufen.
|
||||
- Anschließend bearbeiten wir die Daten mit marcEdit.
|
||||
- Danach schauen wir uns dann noch die Software OpenRefine an und verwenden dazu weitere Beispieldaten.
|
||||
|
||||
## Auswertung der Übung zu DSpace
|
||||
|
||||
* Aufgabe war, von Ihnen erstellte Daten in der DSpace-Demo über die OAI-PMH-Schnittstelle abzurufen und auf der virtuellen Maschine zu speichern.
|
||||
* Falls das nicht geklappt hat, finden Sie hier Beispieldaten: https://pad.gwdg.de/caRGeiZbTD2AyEa7VMVEug
|
||||
* Achtung! Wenn Sie Ihre eigenen Daten aus DSpace verwenden wollen, müssen Sie bitte die erste Zeile durch Folgendes ersetzen:
|
||||
```xml
|
||||
<oai_dc:dc xmlns:oai_dc="http://www.openarchives.org/OAI/2.0/oai_dc/" xmlns:doc="http://www.lyncode.com/xoai" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:dc="http://purl.org/dc/elements/1.1/" xsi:schemaLocation="http://www.openarchives.org/OAI/2.0/oai_dc/ http://www.openarchives.org/OAI/2.0/oai_dc.xsd">
|
||||
```
|
||||
* Ursache: Bei den von Hand aus der OAI-Schnittstelle kopierten Daten fehlen Namespace-Deklarationen. Das würde zu einem Absturz von MarcEdit führen.
|
||||
|
||||
## Austauschprotokolle für Metadaten (OAI-PMH, SRU)
|
||||
|
||||
Es gibt zahlreiche Übertragungsprotokolle im Bibliotheks- und Archivbereich. Drei davon sind besonders weit verbreitet:
|
||||
|
||||
* [Z39.50](https://www.loc.gov/z3950/agency/) (Library of Congress)
|
||||
* [SRU](https://www.loc.gov/sru) - Search/Retrieve via URL (Library of Congress)
|
||||
* [OAI-PMH](https://www.openarchives.org/pmh/) - Open Archives Initiative Protocol for Metadata Harvesting (Open Archives Initiative)
|
||||
|
||||
Note:
|
||||
- Z39.50 ist sehr alt, aber immer noch im Einsatz. Meist wird das modernere SRU als Ergänzung angeboten.
|
||||
- Während Z39.50 und SRU sich besonders für Live-Abfragen oder gezielten Datenabruf mit vielen Parametern eignet, zielt OAI-PMH vor allem auf größere Datenabzüge und regelmäßige Aktualisierungen.
|
||||
- Das Schöne an SRU und OAI-PMH ist, dass die Anfragen als Internetadresse (URL) zusammengestellt werden können und direkt über den Browser ohne Zusatzsoftware aufrufbar sind.
|
||||
|
||||
## Metadaten über OAI-PMH harvesten mit VuFindHarvest
|
||||
|
||||
* Wir "ernten" (harvesten) die über die OAI-PMH-Schnittstellen angebotenen Daten.
|
||||
* Dazu verwenden wir das Tool [VuFindHarvest](https://github.com/vufind-org/vufindharvest), ein OAI Harvester aus dem VuFind-Projekt.
|
||||
* Vorgehen:
|
||||
1. Sicherstellen, dass die OAI-PMH-Endpoints für Koha und ArchivesSpace verfügbar sind
|
||||
2. Mit dem Tool die Daten abrufen und als XML auf der Festplatte speichern
|
||||
|
||||
Note:
|
||||
- VuFind ist ein auf der Suchmaschine Apache Solr basierendes Discovery-System (wie Primo)
|
||||
- VuFindHarvest ist OAI-Harvester (auch unabhängig von VuFind einsetzbar)
|
||||
|
||||
### OAI-PMH Endpoints
|
||||
|
||||
* Koha sollte noch laufen
|
||||
* http://bibliothek.meine-schule.org/cgi-bin/koha/oai.pl
|
||||
* Meldung `No verb supplied` ist OK
|
||||
* Format: `marcxml`
|
||||
* ArchivesSpace muss ggf. gestartet werden
|
||||
* http://localhost:8082
|
||||
* Meldung `Parameter required but no value provided` ist OK
|
||||
* Format: `oai_ead`
|
||||
|
||||
### VuFindHarvest 4.1.0 installieren
|
||||
|
||||
* Die Software wird bei GitHub veröffentlicht: https://github.com/vufind-org/vufindharvest
|
||||
* Sie ist in PHP geschrieben. Für die Installation wird composer (Paketverwaltung für PHP) empfohlen.
|
||||
|
||||
```shell
|
||||
sudo apt update
|
||||
sudo apt install composer php php-xml
|
||||
cd ~
|
||||
wget https://github.com/vufind-org/vufindharvest/archive/v4.1.0.zip
|
||||
unzip v4.1.0.zip
|
||||
cd vufindharvest-4.1.0
|
||||
composer install
|
||||
```
|
||||
|
||||
### Übung: Harvesting
|
||||
|
||||
**Aufgabe (20 Minuten)**
|
||||
|
||||
* Laden Sie mit VuFindHarvest die Daten aus
|
||||
* a) Koha http://bibliothek.meine-schule.org/cgi-bin/koha/oai.pl im Format `marcxml`
|
||||
* b) ArchivesSpace http://localhost:8082 im Format `oai_ead`
|
||||
* Hinweise:
|
||||
* Benutzungshinweise in der [README.md](https://github.com/vufind-org/vufindharvest#usage)
|
||||
* Speichern Sie die Daten in verschiedenen Ordnern.
|
||||
* Beispiel (muss abgewandelt werden):
|
||||
|
||||
```shell
|
||||
cd ~/vufindharvest-4.1.0
|
||||
php bin/harvest_oai.php --url=http://example.com/oai_server --metadataPrefix=oai_dc my_target_dir
|
||||
```
|
||||
|
||||
### Beispieldaten
|
||||
|
||||
* Falls Sie die Übung zu DSpace nicht abschließen konnten oder das Harvesting von Koha und ArchivesSpace nicht geklappt hat, können Sie die Beispieldaten verwenden.
|
||||
* Dokument mit den gesammelten Beispieldaten: https://pad.gwdg.de/caRGeiZbTD2AyEa7VMVEug
|
||||
* Markieren Sie die XML-Daten, kopieren Sie diese in einen Text Editor auf der virtuellen Maschine und speichern Sie die Datei an einer beliebigen Stelle ab.
|
||||
|
||||
## XSLT Crosswalks mit MarcEdit
|
||||
|
||||
* Wir haben nun Daten in verschiedenen Formaten (MARC21-XML, EAD und DC) vorliegen.
|
||||
* Nun werden wir diese einheitlich in MARC21-XML konvertieren.
|
||||
|
||||
### Crosswalks? XSLT?
|
||||
|
||||
* Crosswalks
|
||||
* Gängiger Begriff, um die Konvertierung von einem Metadatenstandard in einen anderen zu beschreiben.
|
||||
* Beispiel: Dublin Core zu MARC21.
|
||||
* Der "Crosswalk" beinhaltet Regeln wie Elemente und Werte zugeordnet werden (sog. Mapping).
|
||||
* Im Idealfall verlustfrei, aber meist keine 1:1-Zuordnung möglich.
|
||||
* XSLT
|
||||
* Programmiersprache zur Transformation von XML-Dokumenten (W3C Empfehlung, 1999)
|
||||
* Literaturempfehlung für Einstieg in XSLT: <https://programminghistorian.org/en/lessons/transforming-xml-with-xsl>
|
||||
|
||||
### MarcEdit 7 installieren
|
||||
|
||||
* MarcEdit ist eine kostenlos nutzbare Software aber nicht Open Source (siehe [Lizenz](https://marcedit.reeset.net/marcedit-end-user-license-agreement))
|
||||
* Sie ist die meistgenutzte Zusatzsoftware für die Arbeit mit MARC21.
|
||||
* Offizielle Webseite: <https://marcedit.reeset.net>
|
||||
* Installation von Mono (MarcEdit ist in .NET geschrieben und benötigt unter Linux diese Laufzeitumgebung) und des Unicode Fonts "Noto":
|
||||
```shell
|
||||
sudo apt install mono-complete fonts-noto
|
||||
```
|
||||
* Installation von MarcEdit:
|
||||
```shell
|
||||
cd ~
|
||||
wget https://marcedit.reeset.net/software/marcedit7/marcedit7.run
|
||||
chmod +x marcedit7.run
|
||||
mkdir ~/marcedit
|
||||
./marcedit7.run --target ~/marcedit
|
||||
```
|
||||
|
||||
### MarcEdit konfigurieren
|
||||
|
||||
* Der Installer hat das Programm MarcEdit im Startmenü (unten links) registriert. Starten Sie darüber das Programm.
|
||||
* Achtung: Die Voreinstellungen in der Linux-Version von MarcEdit sind fehlerhaft. Sie können wie folgt korrigiert werden:
|
||||
* MARC Tools
|
||||
* Button Tools / Edit XML Function List
|
||||
* Für die benötigten Funktionen (EAD=>MARC und OAIDC=>MARCXML):
|
||||
* Im Menü "Defined Functions" die gewünschte Funktion auswählen und Modify klicken
|
||||
* Unter XSLT/XQuery Path `XSLT\` durch `xslt/` ersetzen
|
||||
* Anschließend "Save" und für nächste Funktion wiederholen
|
||||
|
||||
### XSLT Crosswalks anwenden
|
||||
|
||||
**Aufgabe (20 Minuten)**
|
||||
|
||||
* Konvertieren Sie einige Daten aus ArchivesSpace (EAD) und aus DSpace (OAIDC) nach MARC21XML. Speichern Sie die Daten auf der Festplatte.
|
||||
* Im Auswahldialog für die zu konvertierenden Dateien achten Sie bitte darauf, dass der Filter auf "All Files (\*.\*)" gesetzt ist.
|
||||
* Es gibt keine direkte Transformation von EAD zu MARC21XML, Sie benötigen also zwei Schritte:
|
||||
1. EAD -> MARC
|
||||
2. MARC21 -> MARC21XML
|
||||
* Prüfen Sie grob, ob die konvertierten Daten korrekt aussehen.
|
||||
* Anleitung für "XML Conversion" mit MarcEdit von der Unibibliothek aus Illinois: <https://guides.library.illinois.edu/c.php?g=463460&p=3168159>
|
||||
|
||||
Note:
|
||||
- Von MarcEdit verwendete XSLT Dateien liegen auch hier: <https://github.com/reeset/marcedit_xslt_files> und <https://github.com/reeset/marcedit-xslts>
|
||||
|
||||
### Zur Vertiefung
|
||||
|
||||
**Optionale Aufgabe (2 Stunden)**
|
||||
|
||||
* Bearbeiten Sie die [Lehrmaterialien von Library Carpentry zu MarcEdit](https://librarycarpentry.org/lc-marcedit/01-introduction/index.html)
|
||||
|
||||
## Transformation von Metadaten mit OpenRefine
|
||||
|
||||
**Aufgabe (ca. 4 Stunden):** [Library Carpentry Lesson zu OpenRefine](https://librarycarpentry.org/lc-open-refine/)
|
||||
### Einführung in OpenRefine
|
||||
|
||||
### Von OpenRefine unterstützte Formate
|
||||
* Claim
|
||||
* Einsatzbereiche
|
||||
* Anwender\*innen
|
||||
* Formate
|
||||
* Einsatzmöglichkeiten
|
||||
* Historie
|
||||
|
||||
#### Claim von OpenRefine
|
||||
|
||||
> "A free, open source, powerful tool for working with messy data"
|
||||
|
||||
* grafische Oberfläche, die einer klassischen Tabellenverarbeitungssoftware ähnelt
|
||||
* dient der Analyse, Bereinigung, Konvertierung und Anreicherung von Daten
|
||||
* wird in der Regel lokal auf einem Computer installiert und über den Browser bedient
|
||||
|
||||
#### Einsatzbereiche
|
||||
|
||||

|
||||
|
||||
Note:
|
||||
- Aus Umfrage vom OpenRefine-Team, n = 178
|
||||
|
||||
#### Anwender\*innen
|
||||
|
||||

|
||||
|
||||
#### Von OpenRefine unterstützte Formate
|
||||
|
||||
* Besonders geeignet für tabellarische Daten (CSV, TSV, XLS, XLSX und auch TXT mit Trennzeichen oder festen Spaltenbreiten)
|
||||
* Einfaches "flaches" XML (z.B. MARCXML) oder JSON ist mit etwas Übung noch relativ einfach zu modellieren
|
||||
* Komplexes XML mit Hierarchien (z.B. EAD) ist möglich, aber nur mit Zusatztools
|
||||
* Kann in Kombination mit MarcEdit für MARC21 benutzt werden
|
||||
* Kann auch [in Kombination mit MarcEdit](https://blog.reeset.net/archives/1873) für Analyse und Transformation von MARC21 benutzt werden
|
||||
|
||||
### Einsatzmöglichkeiten von OpenRefine
|
||||
#### Einsatzmöglichkeiten von OpenRefine
|
||||
|
||||
* Exploration von Datenlieferungen
|
||||
* Vereinheitlichung und Bereinigung (zur Datenqualität in der Praxis siehe Präsentation von Peter Király ["Validating 126 million MARC records"](https://docs.google.com/presentation/d/e/2PACX-1vRU4J_rln00UVD7pNPT0_02NOad0HfSk_UKqRI0v29y8QkMAplEDlyjc0Ot_VE_paV6WBW29Fh_V-iN/pub))
|
||||
* Abgleich mit Normdaten ("Reconciliation") in Wikidata, GND und VIAF
|
||||
* Für lokalen Einsatz ausgelegt (Installation auf Webservern und Automatisierung möglich, aber nur mit Zusatzsoftware)
|
||||
|
||||
## XSLT Crosswalks mit MarcEdit
|
||||
#### Historie
|
||||
|
||||
**Aufgabe (ca. 4 Stunden):** [Library Carpentry Lesson zu MarcEdit](https://librarycarpentry.org/lc-marcedit/01-introduction/index.html) (noch in Entwicklung, aber brauchbar)
|
||||
|
||||
### Crosswalks? XSLT?
|
||||
|
||||
* Crosswalks
|
||||
* Gängiger Begriff, um die Konvertierung von einem Metadatenstandard in einen anderen zu beschreiben.
|
||||
* Beispiel: MARC21 zu Dublin Core.
|
||||
* Der "Crosswalk" beinhaltet Regeln wie Elemente und Werte zugeordnet/verändert werden müssen.
|
||||
* Im Idealfall verlustfrei, aber meist keine 1:1-Zuordnung möglich.
|
||||
* XSLT
|
||||
* Programmiersprache zur Transformation von XML-Dokumenten (W3C Empfehlung, 1999)
|
||||
* Literaturempfehlung für Einstieg in XSLT: <https://programminghistorian.org/en/lessons/transforming-xml-with-xsl>
|
||||
|
||||
### XSLT mit MarcEdit
|
||||
|
||||
* Anleitung für "XML Conversion" mit MarcEdit von der Unibibliothek aus Illinois: <https://guides.library.illinois.edu/c.php?g=463460&p=3168159>
|
||||
* Von MarcEdit verwendete XSLT Dateien liegen auch hier: <https://github.com/reeset/marcedit_xslt_files> und <https://github.com/reeset/marcedit-xslts>
|
||||
|
||||
### Gruppenarbeit
|
||||
|
||||
**Aufgabe (30 Minuten):**
|
||||
|
||||
* MarcEdit installieren (falls noch nicht erfolgt), siehe Erläuterungen unter <https://librarycarpentry.org/lc-marcedit/01-introduction/index.html>
|
||||
* Beispieldatei herunterladen: <http://demonstrators.ostephens.com/training/data/me-eg-records.mrc>
|
||||
* XSLT Transformationen ausprobieren: Button "MARC Tools"
|
||||
|
||||
## Austauschprotokolle für Metadaten (OAI-PMH, SRU)
|
||||
|
||||
### Schnittstellen SRU, OAI-PMH und Z39.50
|
||||
|
||||
Es gibt zahlreiche Übertragungsprotokolle im Bibliotheks- und Archivbereich. Drei davon sind besonders weit verbreitet:
|
||||
|
||||
* Z39.50 (Library of Congress)
|
||||
* SRU - Search/Retrieve via URL (Library of Congress)
|
||||
* OAI-PMH - Open Archives Initiative Protocol for Metadata Harvesting (Open Archives Initiative)
|
||||
<https://github.com/OpenRefine/OpenRefine/graphs/contributors>
|
||||
|
||||
Note:
|
||||
* Z39.50 ist sehr alt, aber immer noch im Einsatz. Meist wird das modernere SRU als Ergänzung angeboten.
|
||||
* Während Z39.50 und SRU sich besonders für Live-Abfragen oder gezielten Datenabruf mit vielen Parametern eignet, zielt OAI-PMH vor allem auf größere Datenabzüge und regelmäßige Aktualisierungen.
|
||||
* Das Schöne an SRU und OAI-PMH ist, dass die Anfragen als Internetadresse (URL) zusammengestellt werden können und direkt über den Browser ohne Zusatzsoftware aufrufbar sind.
|
||||
- 2010-05: Freebase Gridworks
|
||||
- 2011-12-11: Google Refine 2.5
|
||||
- 2015-04-30: OpenRefine 2.6 rc1
|
||||
- 2017-06-18: OpenRefine 2.7
|
||||
- 2020-09-06: OpenRefine 3.4
|
||||
- 2021-11-07: OpenRefine 3.5.0
|
||||
|
||||
### SRU und OAI am Beispiel von Swissbib
|
||||
### Installation OpenRefine 3.5.0
|
||||
|
||||
Das Projekt swissbib sammelt Metadaten aller schweizer Universitätsbibliotheken, der Nationalbibliothek und einiger Kantonsbibliotheken sowie weiterer Institutionen. Der gemeinsame Katalog ermöglicht eine übergreifende Suche, gleichzeitig bietet swissbib auch Schnittstellen an, über welche Metadaten der teilnehmenden Institutionen zentral bezogen werden können.
|
||||
|
||||
* Dokumentation Swissbib SRU: <http://www.swissbib.org/wiki/index.php?title=SRU>
|
||||
* Dokumentation Swissbib OAI: <http://www.swissbib.org/wiki/index.php?title=Swissbib_oai>
|
||||
|
||||
#### Aufgabe 1
|
||||
|
||||
Lesen Sie die [Dokumentation zur SRU-Schnittstelle von Swissbib](http://www.swissbib.org/wiki/index.php?title=SRU) und stellen Sie eine Abfrage mit folgenden Parametern zusammen:
|
||||
|
||||
* Katalog der Bibliothek der FH Graubünden
|
||||
* Suche über alle Felder nach Suchbegriff: open
|
||||
* Format:MARC XML - swissbib
|
||||
|
||||
Sie können dazu das Formular auf der Webseite <http://sru.swissbib.ch> verwenden oder die URL anhand der Dokumentation selbst zusammenbauen.
|
||||
|
||||
#### Aufgabe 2
|
||||
|
||||
Laden Sie die gleichen Daten in anderen Metadatenstandards (z.B. Dublin Core) und vergleichen Sie.
|
||||
|
||||
Tipp: Öffnen Sie zwei Browserfenster nebeneinander, um die Unterschiede leichter sehen zu können.
|
||||
1. Die OpenRefine-Version für Linux herunterladen
|
||||
```shell
|
||||
cd ~
|
||||
wget https://github.com/OpenRefine/OpenRefine/releases/download/3.5.0/openrefine-linux-3.5.0.tar.gz
|
||||
```
|
||||
2. Das Tar-Archiv entpacken
|
||||
```shell
|
||||
tar -xzf openrefine-linux-3.5.0.tar.gz
|
||||
```
|
||||
3. In den entpackten Ordner wechseln und dort im Terminal den Befehl "./refine" aufrufen
|
||||
```shell
|
||||
cd ~/openrefine-3.5.0
|
||||
./refine
|
||||
```
|
||||
4. Im Firefox-Browser auf der virtuellen Maschine die Adresse http://localhost:3333 aufrufen.
|
||||
|
||||
Note:
|
||||
* Swissbib nutzt XSL Stylesheets, um live bei einer Suchanfrage, die Daten in verschiedene Formate zu konvertieren.
|
||||
- OpenRefine benötigt JAVA. Das haben wir schon auf unserer virtuellen Maschine, weil wir es für ArchivesSpace installiert hatten.
|
||||
- `./` ist unter Linux eine Abkürzung für "in diesem Verzeichnis". Einfach nur `refine` reicht hier nicht aus, weil das Terminal dann nicht sicher weiß, ob Sie einen systemweit installierten Befehl `refine` oder die Datei `refine` im aktuellen Verzeichnis meinen. Daher muss zum Ausführen von Dateien im selben Verzeichnis das `./` vorangestellt werden.
|
||||
|
||||
#### Aufgabe 3
|
||||
### Übung Library Carpentry Lesson
|
||||
|
||||
Lesen Sie die [Dokumentation zur OAI-Schnittstelle von Swissbib](http://www.swissbib.org/wiki/index.php?title=Swissbib_oai).
|
||||
* In den vorigen Semestern haben wir das Kennenlernen von OpenRefine als Hausaufgabe aufgegeben. Das ist wegen dem Ersatztermin diesmal nicht möglich.
|
||||
* Wir gehen deshalb nun ein paar Basisfunktionen gemeinsam durch, damit Sie einen Eindruck von der Software erhalten.
|
||||
* Bei Interesse können Sie die [Lehrmaterialien von Library Carpentry zu OpenRefine](https://librarycarpentry.org/lc-open-refine/) (ca. 4 Stunden) zur Vertiefung durchgehen.
|
||||
* Anschließend nutzen wir OpenRefine, um weitere Daten in MARCXML zu konvertieren.
|
||||
|
||||
Laden Sie einige Datensätze aus dem gesamten Swissbib-Verbund, die seit dem 01.06.2020 verändert wurden im Format MARC21. Speichern Sie die Daten in der Datei `swissbib-2020-06-01.xml`.
|
||||
#### Beispieldaten laden
|
||||
|
||||
#### Bonusaufgabe
|
||||
* Create Project > Web Addresses (URL)
|
||||
* https://raw.githubusercontent.com/LibraryCarpentry/lc-open-refine/gh-pages/data/doaj-article-sample.csv
|
||||
* Automatisch erkannte Einstellungen für den Import können so belassen werden.
|
||||
* Mit Button `Create Project` oben rechts den Import starten.
|
||||
|
||||
Finden Sie heraus, nach welchen Regeln die SRU-Schnittstelle von Swissbib MARC21 in Dublin Core transformiert.
|
||||
#### Vorführung von Basisfunktionen
|
||||
|
||||
Tipp: Nutzen Sie den Explain-Befehl der SRU-Schnittstelle
|
||||
1. Spalte Language > Facet > Text Facet
|
||||
2. Spalte Authors > Edit cells > Split multi-valued cells... > Separator: |
|
||||
3. Spalte Authors > Edit cells > Cluster and edit...
|
||||
4. Spalte Authors > Edit cells > Join multi-valued cells... > Separator: |
|
||||
|
||||
## Weitere Tools zur Metadatentransformation
|
||||
#### Kleine Fingerübungen
|
||||
|
||||
### Zur Motivation
|
||||
1. Spalte Licence > Facet > Text facet
|
||||
* Was ist die am häufigsten vergebene Lizenz
|
||||
* CC BY (954x)
|
||||
* Wieviele Artikel haben keine Lizenz?
|
||||
* 6
|
||||
2. Spalte Publisher > Facet > Text facet
|
||||
* Warum erscheint MDPI AG zweimal?
|
||||
* Eingabe einmal mit 1 Leerschlag, und einmal mit 2
|
||||
* Wie lässt sich das korrigieren?
|
||||
* Edit, Leerzeichen löschen und Apply klicken
|
||||
* Cluster -> merge
|
||||
|
||||
Metadaten-Management in der Praxis, hier beim Leibniz-Informationszentrum Wirtschaft (ZBW) in Hamburg:
|
||||
* Infoseite: <https://www.zbw.eu/de/ueber-uns/arbeitsschwerpunkte/metadaten/>
|
||||
* Videointerview mit Kirsten Jeude: <https://www.youtube.com/watch?v=YwbRTDvt_sA>
|
||||
#### Vorführung Reconciliation
|
||||
|
||||
### Tools
|
||||
* Ziel: Über die ISSN Informationen zur Zeitschrift ergänzen
|
||||
* Spalte Citation > Edit column > Add column based on this column...
|
||||
* Name: Journal
|
||||
* Expression: `value.split(",")[0]`
|
||||
* Spalte Journal > Reconcile > Start reconciling
|
||||
* Wikidata reconci.link (en) auswählen
|
||||
* links "Reconcile against no particular type" auswählen
|
||||
* rechts "ISSNs" aktivieren und in Textfeld ISSN eingeben und P236 anklicken
|
||||
* Spalte Journal > Edit column > Add columns from reconciled values...
|
||||
* official website (P856)
|
||||
* configure: Limit auf 1 setzen
|
||||
|
||||
Prof. Magnus Pfeffer (2016): Open Source Software zur Verarbeitung und Analyse von Metadaten. Präsentation auf dem 6. Bibliothekskongress. <http://nbn-resolving.de/urn/resolver.pl?urn:nbn:de:0290-opus4-24490>
|
||||
### Übung: CSV nach MARCXML mit OpenRefine
|
||||
|
||||
* Catmandu (Perl): <https://librecat.org>
|
||||
* Metafacture (Java): <https://github.com/metafacture/metafacture-core>
|
||||
* OAI harvester für die Kommandozeile: <https://github.com/miku/metha>
|
||||
* siehe auch die vielen Tools zu MARC21: <https://wiki.code4lib.org/Working_with_MARC>
|
||||
* Wir nutzen die Funktion [Templating Exporter](https://docs.openrefine.org/manual/exporting#templating-exporter). Diese findet sich oben rechts im Menü Export > Templating
|
||||
* Beschreibung des MARC21 Formats für bibliografische Daten mit Liste der Felder: <https://www.loc.gov/marc/bibliographic/>
|
||||
* Beispieldatei der Library of Congress für MARC21 mit mehreren Dokumenten: <https://www.loc.gov/standards/marcxml/xml/collection.xml>
|
||||
|
||||
## Nutzung von JSON-APIs
|
||||
Note:
|
||||
- Das Vorgehen ist ähnlich wie bei XSLT Crosswalks, nur dass das "Template" hier direkt bearbeitet werden kann und nicht bereits fest steht, wie bei MarcEdit.
|
||||
- OpenRefine verwendet eine eigene Template-Sprache (GREL) statt XSLT.
|
||||
|
||||
### Beispiel für API: lobid-gnd
|
||||
#### Voraussetzung für die Übung
|
||||
|
||||
<https://lobid.org/gnd/api>
|
||||
* OpenRefine (lokal oder auf dem Server)
|
||||
* Ein Projekt mit den Beispieldaten aus der Library Carpentry Lesson.
|
||||
* Schnell neu zu erstellen mit: Create Project > Web Addresses (URL)
|
||||
* https://raw.githubusercontent.com/LibraryCarpentry/lc-open-refine/gh-pages/data/doaj-article-sample.csv
|
||||
|
||||
* Suchergebnisse als JSON
|
||||
* Datensätze über ID direkt als JSON abrufen
|
||||
* Bulk-Downloads mit JSON lines
|
||||
* Was kann man damit bauen? Beispiel Autovervollständigung
|
||||
#### Vorlage als Ausgangsbasis
|
||||
|
||||
### Beispiel für Tool: ScrAPIr
|
||||
* Prefix:
|
||||
```xml
|
||||
<collection xmlns="http://www.loc.gov/MARC21/slim">
|
||||
```
|
||||
* Row Separator: (Zeilenumbruch)
|
||||
* Suffix:
|
||||
```xml
|
||||
</collection>
|
||||
```
|
||||
|
||||
<https://scrapir.org>
|
||||
* Row Template:
|
||||
|
||||
* Das Tool erlaubt Daten von bekannten Webseiten zu beziehen
|
||||
* genutzt werden dazu die APIs der Webseiten (in der Regel JSON)
|
||||
* es werden auch Vorlagen für Code (Javascript, Python) bereitgestellt
|
||||
* Beispiel YouTube: <https://scrapir.org/data-management?api=YouTube_API>
|
||||
```xml
|
||||
<record>
|
||||
<leader> nab a22 uu 4500</leader>
|
||||
<controlfield tag="001">{{cells['URL'].value.replace('https://doaj.org/article/','').escape('xml')}}</controlfield>
|
||||
<datafield tag="022" ind1=" " ind2=" ">
|
||||
<subfield code="a">{{cells['ISSNs'].value.escape('xml')}}</subfield>
|
||||
</datafield>
|
||||
<datafield tag="100" ind1="0" ind2=" ">
|
||||
<subfield code="a">{{cells['Authors'].value.split('|')[0].escape('xml')}}</subfield>
|
||||
</datafield>
|
||||
<datafield tag="245" ind1="0" ind2="0">
|
||||
<subfield code="a">{{cells["Title"].value.escape('xml')}}</subfield>
|
||||
</datafield>{{
|
||||
forEach(cells['Authors'].value.split('|').slice(1), v ,'
|
||||
<datafield tag="700" ind1="0" ind2=" ">
|
||||
<subfield code="a">' + v.escape('xml') + '</subfield>
|
||||
</datafield>')
|
||||
}}
|
||||
</record>
|
||||
```
|
||||
|
||||
#### Aufgabe 1: "Reverse Engineering"
|
||||
|
||||
* Beschreiben Sie anhand des Vergleichs der Ausgangsdaten mit dem Ergebnis mit ihren eigenen Worten welche Transformationen für die jeweiligen Felder durchgeführt wurden.
|
||||
* Versuchen Sie die Aufgabe in der Gruppenarbeit zunächst einzeln zu lösen (10 min) und diskutieren Sie dann in der Gruppe.
|
||||
* Dokumentieren Sie abschließend bitte hier das Gruppenergebnis.
|
||||
|
||||
#### Aufgabe 2: Template ergänzen
|
||||
|
||||
* Suchen Sie für weitere Spalten in den DOAJ-Daten die Entsprechung in MARC21: <https://www.loc.gov/marc/bibliographic/>
|
||||
* Erstellen Sie geeignete Regeln im Template, um die Daten der gewählten Spalten in MARC21 zu transformieren.
|
||||
* Dokumentieren Sie das gewählte MARC21-Feld und den zugehörigen Abschnitt aus dem Template.
|
||||
* Wenn die Spalten leere Zellen enthalten, dann Funktion `forNonBlank()` nutzen. Beispiel:
|
||||
|
||||
```xml
|
||||
{{
|
||||
forNonBlank(
|
||||
cells['DOI'].value,
|
||||
v,
|
||||
'<datafield tag="024" ind1="7" ind2=" ">
|
||||
<subfield code="a">' + v.escape('xml') + '</subfield>
|
||||
<subfield code="2">doi</subfield>
|
||||
</datafield>',
|
||||
''
|
||||
)
|
||||
}}
|
||||
```
|
||||
|
||||
##### Lösung aus der Vorführung
|
||||
|
||||
```
|
||||
<record>
|
||||
<leader> nab a22 uu 4500</leader>
|
||||
<controlfield tag="001">{{cells['URL'].value.replace('https://doaj.org/article/','').escape('xml')}}</controlfield>
|
||||
<datafield tag="022" ind1=" " ind2=" ">
|
||||
<subfield code="a">{{cells['ISSNs'].value.escape('xml')}}</subfield>
|
||||
</datafield>
|
||||
<datafield tag="100" ind1="0" ind2=" ">
|
||||
<subfield code="a">{{cells['Authors'].value.split('|')[0].escape('xml')}}</subfield>
|
||||
</datafield>
|
||||
<datafield tag="245" ind1="0" ind2="0">
|
||||
<subfield code="a">{{cells["Title"].value.escape('xml')}}</subfield>
|
||||
</datafield>
|
||||
{{forEach(cells['Subjects'].value.split("|"), v,
|
||||
'<datafield tag="650" ind1="0" ind2="4">
|
||||
<subfield code="a">' + v.escape('xml') + '</subfield>
|
||||
</datafield>' + '\n').join('')}}
|
||||
{{
|
||||
forEach(cells['Authors'].value.split('|').slice(1), v ,'
|
||||
<datafield tag="700" ind1="0" ind2=" ">
|
||||
<subfield code="a">' + v.escape('xml') + '</subfield>
|
||||
</datafield>')
|
||||
}}
|
||||
</record>
|
||||
```
|
||||
<record>
|
||||
<leader> nab a22 uu 4500</leader>
|
||||
<controlfield tag="001">{{cells['URL'].value.replace('https://doaj.org/article/','').escape('xml')}}</controlfield>
|
||||
<datafield tag="022" ind1=" " ind2=" ">
|
||||
<subfield code="a">{{cells['ISSNs'].value.escape('xml')}}</subfield>
|
||||
</datafield>
|
||||
<datafield tag="100" ind1="0" ind2=" ">
|
||||
<subfield code="a">{{cells['Authors'].value.split('|')[0].escape('xml')}}</subfield>
|
||||
</datafield>
|
||||
<datafield tag="245" ind1="0" ind2="0">
|
||||
<subfield code="a">{{cells["Title"].value.escape('xml')}}</subfield>
|
||||
</datafield>
|
||||
{{forEach(cells['Subjects'].value.split("|"), v,
|
||||
'<datafield tag="650" ind1="0" ind2="4">
|
||||
<subfield code="a">' + v.escape('xml') + '</subfield>
|
||||
</datafield>' + '\n').join('')}}
|
||||
{{
|
||||
forEach(cells['Authors'].value.split('|').slice(1), v ,'
|
||||
<datafield tag="700" ind1="0" ind2=" ">
|
||||
<subfield code="a">' + v.escape('xml') + '</subfield>
|
||||
</datafield>')
|
||||
}}
|
||||
</record><record>
|
||||
<leader> nab a22 uu 4500</leader>
|
||||
<controlfield tag="001">{{cells['URL'].value.replace('https://doaj.org/article/','').escape('xml')}}</controlfield>
|
||||
<datafield tag="022" ind1=" " ind2=" ">
|
||||
<subfield code="a">{{cells['ISSNs'].value.escape('xml')}}</subfield>
|
||||
</datafield>
|
||||
<datafield tag="100" ind1="0" ind2=" ">
|
||||
<subfield code="a">{{cells['Authors'].value.split('|')[0].escape('xml')}}</subfield>
|
||||
</datafield>
|
||||
<datafield tag="245" ind1="0" ind2="0">
|
||||
<subfield code="a">{{cells["Title"].value.escape('xml')}}</subfield>
|
||||
</datafield>
|
||||
{{forEach(cells['Subjects'].value.split("|"), v,
|
||||
'<datafield tag="650" ind1="0" ind2="4">
|
||||
<subfield code="a">' + v.escape('xml') + '</subfield>
|
||||
</datafield>' + '\n').join('')}}
|
||||
{{
|
||||
forEach(cells['Authors'].value.split('|').slice(1), v ,'
|
||||
<datafield tag="700" ind1="0" ind2=" ">
|
||||
<subfield code="a">' + v.escape('xml') + '</subfield>
|
||||
</datafield>')
|
||||
}}
|
||||
</record>
|
||||
|
||||
#### Aufgabe 3: Validieren mit xmllint
|
||||
|
||||
* Wir exportieren das Gesamtergebnis als XML-Datei.
|
||||
* Tipp: Firefox speichert Datei im Downloads-Ordner als .txt. Ordner Downloads aufrufen und Ende umbenennen in .xml
|
||||
* Für die Validierung können Sie das Programm `xmllint` verwenden, das unter Ubuntu vorinstalliert ist.
|
||||
* Zum Abgleich gegen das offizielle Schema von MARC21 laden wir dieses (XSD) zunächst herunter.
|
||||
|
||||
```shell
|
||||
cd ~/Downloads
|
||||
wget https://www.loc.gov/standards/marcxml/schema/MARC21slim.xsd
|
||||
xmllint doaj-article-sample-csv.xml --noout --schema MARC21slim.xsd
|
||||
```
|
||||
|
||||
Note:
|
||||
- Wenn Sie für das Projekt in OpenRefine nicht den vorgeschlagenen Namen verwendet haben, heißt die gespeicherte Datei bei Ihnen anders.
|
||||
|
||||
#### OpenRefine beenden
|
||||
|
||||
* Im Terminalfenster `STRG` + `C` drücken
|
||||
* Wenn wieder ein blinkender Cursor erscheint, kann das Terminalfenster geschlossen werden mit dem Befehl `exit`
|
||||
|
||||
## Aufgaben
|
||||
|
||||
Bis zum nächsten Termin:
|
||||
|
||||
1. Beitrag im Lerntagebuch zu dieser Lehreinheit (3000 - 4000 Zeichen)
|
||||
2. Installation VuFind (siehe unten) bitte möglichst frühzeitig, damit wir bei Problemen noch unterstützen können
|
||||
3. Übung "Konfiguration Suche und Facetten" (siehe unten) und dazu einen Beitrag im Lerntagebuch verfassen (1000-2000 Zeichen)
|
||||
|
||||
### Installation VuFind
|
||||
|
||||
#### Installation VuFind 8.0.2
|
||||
|
||||
Installation nach offizieller Anleitung für VuFind unter Ubuntu: <https://vufind.org/wiki/installation:ubuntu>
|
||||
|
||||
Es folgen die relevanten Auszüge und Hinweise/Erklärungen dazu.
|
||||
|
||||
##### VuFind on Ubuntu
|
||||
|
||||
> These instructions assume that you are starting with a clean installation of Ubuntu. If you already have an Ubuntu server, you will be able to skip some steps, but you may have to reconfigure some existing software.
|
||||
|
||||
Zur Erinnerung: Best Practice ist die Installation von einer Anwendung pro Server (durch Virtualisierung und Container heute einfach möglich).
|
||||
|
||||
##### Version Requirements
|
||||
|
||||
> These instructions were most recently tested on Ubuntu 20.04 (...)
|
||||
|
||||
Gut für uns, weil wir für unsere virtuelle Maschine Ubuntu 20.04 LTS verwenden.
|
||||
|
||||
##### Installing VuFind from the DEB Package
|
||||
|
||||
> The easiest way to get VuFind up and running is to install it from the DEB package.
|
||||
|
||||
VuFind stellt ein Installationspaket bereit. Unter Linux gibt es viele verschiedene Formate für Installationspakete. Für Ubuntu und Debian gibt es DEB, für Fedora und SUSE beispielsweise RPM. Wir starten die Installation wie vorgegeben:
|
||||
|
||||
```shell
|
||||
wget https://github.com/vufind-org/vufind/releases/download/v8.0.2/vufind_8.0.2.deb
|
||||
sudo dpkg -i vufind_8.0.2.deb
|
||||
```
|
||||
|
||||
Es erscheint eine Fehlermeldung, dass noch nicht alle von VuFind benötigten Pakete installiert sind. Zunächst aktualisieren wir das Paketverzeichnis (Nachtrag 14.12.):
|
||||
|
||||
```shell
|
||||
sudo apt-get update
|
||||
```
|
||||
|
||||
Dann lassen wir die benötigten Pakete mit installieren:
|
||||
|
||||
```shell
|
||||
sudo apt-get install -f
|
||||
```
|
||||
|
||||
##### Important Notes / Database Issues
|
||||
|
||||
Hier ist ein Fehler in der Anleitung. Ubuntu 20.04 wird mit MariaDB ausgeliefert und nicht mit MySQL. Für uns ist daher "Case 4 - MariaDB" relevant.
|
||||
|
||||
##### MariaDB Passwort für root
|
||||
|
||||
> If you are using a distribution that includes MariaDB instead of MySQL, you will not be prompted to set a root password during installation. Instead, you should run “sudo /usr/bin/mysql_secure_installation” to properly set up security.
|
||||
|
||||
```shell
|
||||
sudo /usr/bin/mysql_secure_installation
|
||||
```
|
||||
|
||||
* Das aktuelle Passwort ist leer (Enter drücken).
|
||||
* Neues Passwort vergeben (und merken!).
|
||||
* Die voreingestellten Antworten sind OK (alle Fragen können mit Enter bestätigt werden).
|
||||
|
||||
##### MariaDB Zugriff auf root erlauben
|
||||
|
||||
> (...) you may also need to disable the root account's “unix_socket” plugin, which prevents regular logins. You can do this by logging in with “sudo mysql -uroot -p” and then running "UPDATE mysql.user SET plugin='' WHERE User='root'; FLUSH PRIVILEGES;"
|
||||
|
||||
Der im Zitat beschriebene Weg würde funktionieren. Einfacher ist die Eingabe der SQL-Befehle als Einzeiler:
|
||||
|
||||
```shell
|
||||
sudo mysql -uroot -p -e "UPDATE mysql.user SET plugin='' WHERE User='root'; FLUSH PRIVILEGES;"
|
||||
```
|
||||
|
||||
##### Important Notes / (Ende)
|
||||
|
||||
> You may want to restart your system one more time to be sure all the new settings are in place, or at least make sure appropriate environment variable settings are loaded by running: `source /etc/profile`
|
||||
|
||||
Ein Neustart ist in unserem Fall nicht erforderlich. Es reicht aus, den genannten Befehl einzugeben:
|
||||
|
||||
```shell
|
||||
source /etc/profile
|
||||
```
|
||||
|
||||
##### Abweichend von der Installationsanleitung: Dateirechte anpassen
|
||||
|
||||
* Wir starten Solr gleich "von Hand", d. h. mit den Rechten des Accounts, mit dem wir gerade an der VM angemeldet sind. Die VuFind-Installation sieht jedoch vor, mit den Rechten des ersten regulären Accounts gestartet zu werden.
|
||||
* Wir übertragen diese Rechte also nun auf unseren Account und belassen die Rechte für das Cache- und das Config-Verzeichnis beim Account des Webservers (www-data).
|
||||
|
||||
```shell
|
||||
sudo chown -R $USER:$GROUP /usr/local/vufind
|
||||
sudo chown -R www-data:www-data /usr/local/vufind/local/cache
|
||||
sudo chown -R www-data:www-data /usr/local/vufind/local/config
|
||||
```
|
||||
|
||||
##### Configuring and starting VuFind / Start solr
|
||||
|
||||
```shell
|
||||
/usr/local/vufind/solr.sh start
|
||||
```
|
||||
|
||||
Die Warnungen zu den Limits können erstmal ignoriert werden. In der Doku von VuFind ist beschrieben, wie sich das korrigieren ließe: <https://vufind.org/wiki/administration:starting_and_stopping_solr>
|
||||
|
||||
##### Configuring and starting VuFind / Configure VuFind
|
||||
|
||||
> Open a web browser, and browse to this URL: <http://your-server-name/vufind/Install/Home> (Replace “your-server-name” with the address you wish to use to access VuFind; replace “vufind” with your custom base path if you changed the default setting during installation).
|
||||
|
||||
Wir haben keinen Domainnamen. Daher verwenden wir `localhost`. Öffnen Sie den Browser in der virtuellen Maschine (Linux) und rufen Sie die folgende Adresse auf:
|
||||
|
||||
http://localhost/vufind/Install/Home
|
||||
|
||||
##### Configuring and starting VuFind / Auto-Configuration
|
||||
|
||||
> If installation was successful, you should now see an Auto Configure screen. Some items on the list will be marked “Failed” with “Fix” links next to them. Click on each Fix link in turn and follow the on-screen instructions. (...) After an issue is successfully resolved, you can click the “Auto Configure” breadcrumb to go back to the main list and proceed to the next problem.
|
||||
|
||||
Die meisten Punkte können ohne weitere Angaben "gefixt" werden. Nur die beiden Punkte Database und ILS erfordern weitere Angaben.
|
||||
|
||||
##### Configuring and starting VuFind / Auto-Configuration / Database
|
||||
|
||||
Bei der Datenbank muss ein neues Passwort vergeben sowie das zuvor oben im Abschnitt "MariaDB Passwort für root" eingegeben werden.
|
||||
|
||||
##### Configuring and starting VuFind / Auto-Configuration / ILS
|
||||
|
||||
Wir haben kein Bibliothekssystem, daher wählen wir NoILS. Dann wird aber trotzdem noch "Failed" angezeigt und wenn wir nochmal auf "Fix" klicken erscheint die folgende Meldung:
|
||||
|
||||
> (...) You may need to edit the file at /usr/vufind/local/config/vufind/NoILS.ini
|
||||
|
||||
1. Datei im Texteditor (gedit) mit Administratorrechten öffnen
|
||||
|
||||
```shell
|
||||
sudo gedit /usr/local/vufind/local/config/vufind/NoILS.ini
|
||||
```
|
||||
|
||||
2. In Zeile 3 `ils-offline` in `ils-none` ändern und speichern.
|
||||
|
||||
##### Weitere Sicherheitseinstellungen
|
||||
|
||||
* Die in den Abschnitten [Locking Down Configurations](https://vufind.org/wiki/installation:ubuntu#locking_down_configurations) und [4. Secure your system](https://vufind.org/wiki/installation:ubuntu#secure_your_system) beschriebenen Einstellungen benötigen wir für unsere Testinstallation nicht.
|
||||
|
||||
#### Fehlerbehebung
|
||||
|
||||
Falls etwas schief geht, können die folgenden Befehle helfen die Installation teilweise oder ganz zurückzusetzen.
|
||||
|
||||
##### Fall 1: Auto Configuration ist nicht mehr erreichbar
|
||||
|
||||
* Problem: Die Seite "Auto Configuration" unter http://localhost/vufind/Install/Home war schon einmal aufrufbar, aber kann nun nicht mehr geladen werden.
|
||||
* Ursache: Die Konfiguration ist defekt und kann von VuFind nicht mehr gelesen werden.
|
||||
* Lösung:
|
||||
* Die lokale Konfiguration (im Verzeichnis /usr/local/vufind/local/) manuell löschen.
|
||||
|
||||
```shell
|
||||
sudo rm /usr/local/vufind/local/config/vufind/config.ini
|
||||
```
|
||||
|
||||
* Datenbank und Nutzer löschen (bei der folgenden Abfrage das Root-Passwort für MariaDB eingeben, das oben festgelegt wurde)
|
||||
|
||||
```shell
|
||||
sudo mysql -uroot -p -e "DROP DATABASE IF EXISTS vufind; DROP USER IF EXISTS vufind@localhost;"
|
||||
```
|
||||
|
||||
* Danach die Seite "Auto Configuration" aufrufen und die Konfiguration erneut versuchen.
|
||||
|
||||
##### Fall 2: Auto Configuration kann gar nicht aufgerufen werden
|
||||
|
||||
* Problem: Die Seite "Auto Configuration" http://localhost/vufind/Install/Home kann nicht aufgerufen werden oder liefert nur eine leere weiße Seite zurück.
|
||||
* Ursache: Bei der Installation ist etwas schief gegangen.
|
||||
* Lösung:
|
||||
* Installation von VuFind vollständig löschen
|
||||
|
||||
```shell
|
||||
sudo dpkg -P vufind
|
||||
```
|
||||
|
||||
```shell
|
||||
sudo rm -rf /usr/local/vufind
|
||||
sudo rm /etc/apache2/conf-enabled/vufind.conf
|
||||
```
|
||||
|
||||
* Datenbank und Nutzer löschen (bei der folgenden Abfrage das Root-Passwort für MariaDB eingeben, das oben festgelegt wurde)
|
||||
|
||||
```shell
|
||||
sudo mysql -uroot -p -e "DROP DATABASE IF EXISTS vufind; DROP USER IF EXISTS vufind@localhost;"
|
||||
```
|
||||
|
||||
* Danach Installation noch einmal ganz von vorne beginnen. Dabei Befehle Zeile für Zeile eingeben und auf Fehlermeldungen achten.
|
||||
|
||||
##### Fall 3: Root-Passwort für MariaDB vergessen
|
||||
|
||||
* Problem: Sie haben das Root-Passwort für MariaDB vergessen und können daher weder die "Auto Configuration" abschließen noch von vorne beginnen, weil sie die Datenbank von VuFind nicht löschen können.
|
||||
* Fehlerbeschreibung: Der Aufruf der Befehle beginnend mit `sudo mysql -uroot -p` schlägt bei der Passworteingabe fehl.
|
||||
* Lösung: Aus Sicherheitsgründen ist das Zurücksetzen des Root-Passworts für MariaDB etwas komplizierter. Folgen Sie diesem Tutorial bei Digital Ocean: [How To Reset Your MySQL or MariaDB Root Password on Ubuntu 20.04](https://www.digitalocean.com/community/tutorials/how-to-reset-your-mysql-or-mariadb-root-password-on-ubuntu-20-04)
|
||||
|
||||
#### Testimport
|
||||
|
||||
* Ohne Inhalte lässt sich VuFind schlecht erproben. Daher laden wir zunächst ein paar Daten in das System.
|
||||
* VuFind liefert für Tests einige Dateien mit. Wir laden einige davon im MARC21-Format.
|
||||
|
||||
```shell
|
||||
/usr/local/vufind/import-marc.sh /usr/local/vufind/tests/data/journals.mrc
|
||||
/usr/local/vufind/import-marc.sh /usr/local/vufind/tests/data/geo.mrc
|
||||
/usr/local/vufind/import-marc.sh /usr/local/vufind/tests/data/authoritybibs.mrc
|
||||
```
|
||||
* Anschließend sollten in der Suchoberfläche unter <http://localhost/vufind> ca. 250 Datensätze enthalten sein.
|
||||
|
||||
### Übung: Konfiguration Suche und Facetten
|
||||
|
||||
* Schauen Sie sich das offizielle Einführungsvideo [Configuring Search and Facet Settings](https://www.youtube.com/watch?v=qFbW8u9UQyM&list=PL5_8_wT3JpgE5rv38PwE2ulKlgzBY389y&index=4) an.
|
||||
* Ein Transkript ist auch auf der Seite <https://vufind.org/wiki/videos:configuring_search_and_facet_settings> verfügbar.
|
||||
* Versuchen Sie ausgewählte Inhalte des Videos in Ihrer Installation nachzuvollziehen.
|
||||
|
||||
Note:
|
||||
- Um die Bearbeitung der im Video benannten Konfigurationsdateien (.ini) zu erleichtern, können Sie die Dateiberechtigungen wie folgt ihrem Account zuordnen. Wir hatten diese für die Auto-Configuration beim Webserver (www-data) belassen.
|
||||
|
||||
```shell
|
||||
sudo chown -R $USER:$GROUP /usr/local/vufind/local/config
|
||||
```
|
||||
|
||||
@ -1,20 +1,10 @@
|
||||
# Suchmaschinen und Discovery-Systeme
|
||||
|
||||
1. Funktion von Suchmaschinen am Beispiel von Solr (15 Minuten)
|
||||
2. Installation und Konfiguration von VuFind (120 Minuten)
|
||||
3. Marktüberblick Discovery-Systeme (15 Minuten)
|
||||
|
||||
## Funktion von Suchmaschinen am Beispiel von Solr
|
||||
|
||||
**Aufgabe (ca. 2 Stunden):** [Solr Tutorial](https://lucene.apache.org/solr/guide/8_5/solr-tutorial.html)
|
||||
|
||||
### Zur Einordnung von Solr
|
||||
|
||||
* Solr ist zusammen mit Elasticsearch quasi "Industriestandard".
|
||||
* Solr kann verschiedene Dateiformate (.doc, .xml .json, .ppt usw.) importieren.
|
||||
* Üblicherweise sollte vor dem Import der Daten in einem Schema festgelegt werden welche Felder existieren und welche Datentypen diese beinhalten dürfen.
|
||||
* Solr hat zwar eine integrierte Suchoberfläche, aber diese ist nur zu Demo-Zwecken gedacht.
|
||||
* Das Discovery-System VuFind basiert auf Solr (ebenso wie viele kommerzielle Lösungen wie z.B. Ex Libris Primo).
|
||||
* Installation und Konfiguration von VuFind
|
||||
* Funktion von Suchmaschinen am Beispiel von Solr
|
||||
* Übung zur Datenintegration
|
||||
* Marktüberblick Discovery-Systeme
|
||||
* Zwischenfazit
|
||||
|
||||
## Installation und Konfiguration von VuFind
|
||||
|
||||
@ -26,160 +16,144 @@
|
||||
* Beispiel TU Hamburg: <https://katalog.tub.tuhh.de>
|
||||
* Beispiel UB Leipzig: <https://katalog.ub.uni-leipzig.de>
|
||||
|
||||
### Installation
|
||||
### Installation VuFind 8.0.2
|
||||
|
||||
Gemeinsame Installation nach offizieller Anleitung für VuFind unter Ubuntu: <https://vufind.org/wiki/installation:ubuntu>
|
||||
* Installation war [Aufgabe zur heutigen Sitzung](05_metadaten-modellieren-und-schnittstellen-nutzen.md#Aufgaben).
|
||||
|
||||
Es folgen die relevanten Auszüge und Hinweise/Erklärungen dazu.
|
||||
### Konfiguration Suche und Facetten
|
||||
|
||||
#### VuFind on Ubuntu
|
||||
* Testweise konfigurieren war [Aufgabe zur heutigen Sitzung](05_metadaten-modellieren-und-schnittstellen-nutzen.md#Aufgaben).
|
||||
|
||||
> These instructions assume that you are starting with a clean installation of Ubuntu. If you already have an Ubuntu server, you will be able to skip some steps, but you may have to reconfigure some existing software.
|
||||
## Funktion von Suchmaschinen am Beispiel von Solr
|
||||
|
||||
Zur Erinnerung: Best Practice ist die Installation von einer Anwendung pro Server (durch Virtualisierung und Container heute einfach möglich).
|
||||
* Zur Einordnung von Solr
|
||||
* Sichtung von Solr in VuFind
|
||||
|
||||
#### Version Requirements
|
||||
### Zur Einordnung von Solr
|
||||
|
||||
> These instructions were most recently tested on Ubuntu 19.10 and Debian 10.1 (...)
|
||||
* Solr ist zusammen mit Elasticsearch quasi "Industriestandard".
|
||||
* Üblicherweise sollte vor dem Import der Daten in einem Schema festgelegt werden welche Felder existieren und welche Datentypen diese beinhalten dürfen.
|
||||
* Solr hat zwar eine integrierte Suchoberfläche, aber diese ist nur zu Demo-Zwecken gedacht.
|
||||
* Das Discovery-System VuFind basiert auf Solr (ebenso wie viele kommerzielle Lösungen wie z.B. Ex Libris Primo).
|
||||
|
||||
Gut für uns, weil wir für unsere virtuelle Maschine Ubuntu Server 19.10 verwenden.
|
||||
### Suchindex (Solr) oder Datenbank (MySQL)?
|
||||
|
||||
#### Installing VuFind from the DEB Package
|
||||
| Solr | MySQL |
|
||||
| ------------------------ | ----------------------- |
|
||||
| flache Dokumente | relationale Datensätze |
|
||||
| lexikalische Suche | reiner Glyphenvergleich |
|
||||
| keine Konsistenzprüfung | Transaktionssicherheit |
|
||||
| statische Daten | veränderliche Daten |
|
||||
| -> **Retrieval** (Suche) | -> **Storage** (CRUD) |
|
||||
|
||||
> The easiest way to get VuFind up and running is to install it from the DEB package.
|
||||
* [CRUD](https://de.wikipedia.org/wiki/CRUD): **C**reate, **R**ead, **U**pdate, **D**elete
|
||||
|
||||
VuFind stellt ein Installationspaket bereit. Unter Linux gibt es viele verschiedene Formate für Installationspakete. Für Ubuntu und Debian gibt es DEB, für Fedora und SUSE beispielsweise RPM.
|
||||
### Sichtung von Solr in VuFind
|
||||
|
||||
```
|
||||
wget https://github.com/vufind-org/vufind/releases/download/v6.1.1/vufind_6.1.1.deb
|
||||
sudo dpkg -i vufind_6.1.1.deb
|
||||
sudo apt-get install -f
|
||||
* Administrationsoberfläche: <http://localhost:8983>
|
||||
* Bibliografische Daten im Index "biblio": <http://localhost:8983/solr/#/biblio>
|
||||
* Technische Suchoberfläche in Solr für Index "biblio": <http://localhost:8983/solr/#/biblio/query>
|
||||
* Schema des Index "biblio": <http://localhost:8983/solr/#/biblio/schema>
|
||||
* Erläuterung der VuFind-Felder in VuFind Doku: <https://vufind.org/wiki/development:architecture:solr_index_schema>
|
||||
|
||||
Note:
|
||||
- Ggf. müssen Sie Solr neustarten, falls Sie zwischenzeitlich Ihre VM neu gebootet haben:
|
||||
|
||||
```shell
|
||||
/usr/local/vufind/solr.sh start
|
||||
```
|
||||
|
||||
#### Important Notes / Database Issues
|
||||
### Übung: Suche in VuFind vs. Suche in Solr
|
||||
|
||||
Hier ist ein Fehler in der Anleitung. Ubuntu Server 19.10 wird mit MariaDB ausgeliefert und nicht mit MySQL. Für uns ist daher "Case 4 - MariaDB" relevant.
|
||||
|
||||
#### MariaDB Passwort für root
|
||||
|
||||
> If you are using a distribution that includes MariaDB instead of MySQL, you will not be prompted to set a root password during installation. Instead, you should run “sudo /usr/bin/mysql_secure_installation” to properly set up security.
|
||||
|
||||
```
|
||||
sudo /usr/bin/mysql_secure_installation
|
||||
```
|
||||
|
||||
* Das aktuelle Passwort ist leer (Enter drücken).
|
||||
* Die voreingestellten Antworten sind ok (alle Fragen können mit Enter bestätigt werden).
|
||||
|
||||
#### MariaDB Zugriff auf root erlauben
|
||||
|
||||
> (...) you may also need to disable the root account's “unix_socket” plugin, which prevents regular logins. You can do this by logging in with “sudo mysql -uroot -p” and then running "UPDATE mysql.user SET plugin='' WHERE User='root'; FLUSH PRIVILEGES;"
|
||||
|
||||
1. MySQL Administration öffnen (und Passwort eingeben)
|
||||
* Suchen in VuFind: http://localhost/vufind
|
||||
* Beispielsweise nach `psychology`
|
||||
* Suchen in Admin-Oberfläche von Solr: http://localhost:8983/solr/#/biblio/query
|
||||
* im Feld q mit Feldname:Suchbegriff. Beispiel: `allfields:psychology`
|
||||
* unten links Button "Execute Query"
|
||||
* Parallel Logdatei von Solr anschauen in einem Terminal
|
||||
```shell
|
||||
less +F /usr/local/vufind/solr/vufind/logs/solr.log
|
||||
```
|
||||
sudo mysql -uroot -p
|
||||
```
|
||||
2. Konfigurationsbefehl eingeben
|
||||
```
|
||||
UPDATE mysql.user SET plugin='' WHERE User='root'; FLUSH PRIVILEGES;
|
||||
```
|
||||
3. MySQL Administration schließen
|
||||
```
|
||||
exit;
|
||||
```
|
||||
#### Important Notes / (Ende)
|
||||
* Notieren Sie Unterschiede und Auffälligkeiten im gemeinsamen Dokument
|
||||
|
||||
> You may want to restart your system one more time to be sure all the new settings are in place, or at least make sure appropriate environment variable settings are loaded by running: `source /etc/profile`
|
||||
Note:
|
||||
- Das Programm `less` kann bei Bedarf im Terminal beendet werden mit der Tastenkombination `STRG` + `C` (für interrupt) und dann der Taste `q` (für quit).
|
||||
|
||||
Ein Neustart ist in unserem Fall nicht erforderlich. Es reicht aus, den genannten Befehl einzugeben:
|
||||
### Literatur zu Solr
|
||||
|
||||
```
|
||||
source /etc/profile
|
||||
* Das offizielle Handbuch zu Solr beinhaltet ein gutes Tutorial (ca. 2 Stunden): <https://lucene.apache.org/solr/guide/8_7/solr-tutorial.html>
|
||||
|
||||
## Übung zur Datenintegration
|
||||
|
||||
Ziel: Import der mit MarcEdit und OpenRefine konvertierten Daten aus Koha, ArchivesSpace, DSpace und DOAJ in VuFind
|
||||
|
||||
### Testdaten löschen
|
||||
|
||||
Quelle: https://vufind.org/wiki/indexing:re-indexing
|
||||
|
||||
```shell
|
||||
/usr/local/vufind/solr.sh stop
|
||||
rm -rf /usr/local/vufind/solr/vufind/biblio/index /usr/local/vufind/solr/vufind/biblio/spell*
|
||||
/usr/local/vufind/solr.sh start
|
||||
```
|
||||
|
||||
#### Configuring and starting VuFind / Start solr
|
||||
### Aufgabe für die Gruppenarbeit
|
||||
|
||||
```
|
||||
cd /usr/local/vufind/
|
||||
./solr.sh start
|
||||
```
|
||||
* Importieren Sie alle in MARCXML konvertierten Daten. Gehen Sie dabei wie folgt vor:
|
||||
1. Laden und entpacken Sie [die Beispieldaten](https://bain.felixlohmeier.de/data/vufind-testdaten.zip). Gerne können Sie zusätzlich Ihre selbst in MARCXML konvertierten Daten verwenden.
|
||||
* Wenn Sie nach Klick auf den Downloadlink das Programm "Archive Manager" auswählen, können Sie die enthaltenen Verzeichnisse und Dateien bequem über den Button "Extract" in ein beliebiges Verzeichnis speichern.
|
||||
* Wir gehen im Folgenden vom Verzeichnis `Downloads` aus.
|
||||
2. Bearbeiten Sie vor dem Import die Datei `marc_local.properties` um den Daten eine "collection" zuzuweisen.
|
||||
```shell
|
||||
gedit /usr/local/vufind/import/marc_local.properties
|
||||
```
|
||||
3. Starten Sie das Importscript für die erste Datenquelle. Beispiel für Koha:
|
||||
```shell
|
||||
for f in ~/Downloads/koha/*.xml; do /usr/local/vufind/import-marc.sh $f; done
|
||||
```
|
||||
4. Wiederholen Sie die Schritte 2 und 3 für die übrigen Datenquellen.
|
||||
* Achtung: Der Import der Beispieldaten von ArchivesSpace und DSpace schlägt fehl. Finden Sie die Ursache.
|
||||
* Fügen Sie am Ende der Übung einen Screenshot der Trefferliste einer "leeren" Suche in das gemeinsame Dokument ein.
|
||||
|
||||
Die Warnungen zu den Limits können erstmal ignoriert werden. In der Doku von VuFind ist beschrieben, wie sich das korrigieren ließe: <https://vufind.org/wiki/administration:starting_and_stopping_solr>
|
||||
|
||||
#### Configuring and starting VuFind / Configure VuFind
|
||||
|
||||
> Open a web browser, and browse to this URL: <http://your-server-name/vufind/Install/Home> (Replace “your-server-name” with the address you wish to use to access VuFind; replace “vufind” with your custom base path if you changed the default setting during installation).
|
||||
|
||||
Wir haben keinen Domainnamen. Daher verwenden wir `localhost`. Öffnen Sie den Browser in der virtuellen Maschine (Linux) und rufen Sie die folgende Adresse auf:
|
||||
|
||||
<http://localhost/vufind/Install/Home>
|
||||
|
||||
#### Configuring and starting VuFind / Auto-Configuration
|
||||
|
||||
> If installation was successful, you should now see an Auto Configure screen. Some items on the list will be marked “Failed” with “Fix” links next to them. Click on each Fix link in turn and follow the on-screen instructions. (...) After an issue is successfully resolved, you can click the “Auto Configure” breadcrumb to go back to the main list and proceed to the next problem.
|
||||
|
||||
Die meisten Punkte können ohne weitere Angaben "gefixt" werden. Nur die beiden Punkte Database und ILS erfordern weitere Angaben.
|
||||
|
||||
#### Configuring and starting VuFind / Auto-Configuration / Database
|
||||
|
||||
Bei der Datenbank muss ein neues Passwort vergeben und das zuvor oben im Abschnitt "MariaDB Passwort für root" eingegeben werden.
|
||||
|
||||
#### Configuring and starting VuFind / Auto-Configuration / ILS
|
||||
|
||||
Wir haben kein Bibliothekssystem, daher wählen wir NoILS. Dann wird aber trotzdem noch "Failed" angezeigt und wenn wir nochmal auf "Fix" klicken erscheint die folgende Meldung:
|
||||
|
||||
> (...) You may need to edit the file at /usr/vufind/local/config/vufind/NoILS.ini
|
||||
|
||||
1. Datei mit Texteditor nano öffnen
|
||||
```
|
||||
sudo nano /usr/local/vufind/local/config/vufind/NoILS.ini
|
||||
```
|
||||
2. In Zeile 3 `ils-offline` in `ils-none` ändern.
|
||||
|
||||
3. nano beenden mit CTRL+X und bestätigen (y)
|
||||
|
||||
|
||||
#### Weitere Sicherheitseinstellungen
|
||||
|
||||
Die in den Abschnitten [Locking Down Configurations](https://vufind.org/wiki/installation:ubuntu#locking_down_configurations) und [4. Secure your system](https://vufind.org/wiki/installation:ubuntu#secure_your_system) beschriebenen Einstellungen benötigen wir für unsere Testinstallation nicht.
|
||||
|
||||
#### Falls etwas schief geht...
|
||||
|
||||
* Bei Mehreren ist das Problem aufgetreten, dass die Seite "Auto Configuration" nicht mehr geladen werden konnte. Auch ein Drüberinstallieren und Entfernen und Neuinstallieren von VuFind hat nicht geholfen.
|
||||
* Ursache: Lokale Konfiguration (im Verzeichnis /usr/local/vufind/local/) wird beim Drüberinstallieren und Entfernen nicht angetastet.
|
||||
* Lösung: Lokale Konfigurationsdatei manuell löschen
|
||||
```
|
||||
sudo rm /usr/local/vufind/local/config/vufind/config.ini
|
||||
```
|
||||
* Danach ist die Seite "Auto Configuration" wieder aufrufbar.
|
||||
|
||||
## Konfiguration
|
||||
|
||||
Gruppenarbeit: Bearbeiten Sie die Kapitel 4-9 von folgendem Tutorial: https://felixlohmeier.gitbooks.io/vufind-tutorial-de/content/04_Installation_Testimport.html
|
||||
|
||||
Das Tutorial wurde ursprünglich von Stefan Niesner im Rahmen einer [Projektarbeit](http://malisprojekte.web.th-koeln.de/wordpress/stefan-niesner/) entwickelt und von mir für VuFind 4.1 aktualisiert.
|
||||
|
||||
#### Hinweise
|
||||
|
||||
* Der Befehl zum Kopieren der facets.ini schlägt fehl (`cp /usr/local/vufind/config/vufind/facets.ini /usr/local/vufind/local/config/vufind`). Es hilft ein Kopieren mit Administrationsrechten (`sudo` voranstellen). Gleiches gilt für die Bearbeitung der Konfigurationsdateien (`sudo` voranstellen).
|
||||
* Das Ändern der Sprache funktioniert ggf. nur, wenn `browserDetectLanguage` auf `false` gesetzt wird.
|
||||
* Kapitel 7 scheitert mit einem "Permission denied", hier muss das Tutorial überarbeitet werden. Bitte dieses Kapitel überspringen.
|
||||
|
||||
#### Ergebnis
|
||||
|
||||
So sollte es aussehen, wenn die Kapitel 4-9 des Tutorials bearbeitet wurden:
|
||||
|
||||

|
||||
Note:
|
||||
- Die Beispieldaten umfassen die in den vergangenen Lehreinheiten mit MarcEdit und OpenRefine prozessierten Daten sowie den Export aus Koha. Wir stellen Sie hier bereit, damit Sie einheitliche Daten zur Verfügung haben auch wenn bei den vorherigen Aufgaben etwas durcheinandergekommen ist.
|
||||
|
||||
## Marktüberblick Discovery-Systeme
|
||||
|
||||
### International
|
||||
### International (kommerziell)
|
||||
|
||||
Jährlicher Library Systems Report von Marshall Breeding im ALA Magazine: <https://americanlibrariesmagazine.org/2020/05/01/2020-library-systems-report/>
|
||||
* Jährlicher Library Systems Report von Marshall Breeding im ALA Magazine: <https://americanlibrariesmagazine.org/2020/05/01/2020-library-systems-report/>
|
||||
* [Suche auf librarytechnology.org](https://librarytechnology.org/products/main.pl) vermittelt guten Überblick
|
||||
* siehe auch [Statistik der Verkaufszahlen](https://librarytechnology.org/products/sales/)
|
||||
* Marktführer ist Ex Libris mit [Primo](https://exlibrisgroup.com/de/produkte/primo/inhalts-index/)
|
||||
* Alternative: OCLC mit [WorldCat Discovery](https://www.oclc.org/de/worldcat-discovery.html)
|
||||
* Alternative: EBSCO mit [EDS](https://www.ebsco.com/de-de/wissenschaftliche-bibliotheken/produkte/ebsco-discovery-service)
|
||||
* (Summon wird zugunsten von Primo abgekündigt)
|
||||
|
||||
Anhängende Statistik gibt einen guten Überblick:
|
||||
<https://americanlibrariesmagazine.org/wp-content/uploads/2020/04/charts-for-2020-Library-Systems-Report.pdf>
|
||||
Note:
|
||||
- Den Library Systems Report hatten wir uns zuvor bereits angeschaut, damals jedoch mit Blick auf Bibliothekssysteme. Marshall Breeding führt in seinem Bericht aber auch Discovery-Systeme auf.
|
||||
- Die Funktionalität eines Discovery-Systems besteht aus mindestens zwei Komponenten: Der Software und den Daten.
|
||||
- Kommerzielle Discovery-Systeme verkaufen einen Suchindex meist separat, der vor allem Metadaten zu elektronischen Artikeln enthält.
|
||||
|
||||
### International (Open Source)
|
||||
|
||||
* Open Source-Alternative: [VuFind](https://vufind.org/vufind/) (ohne eigenen Artikelindex)
|
||||
* Nische: [typo3-find](https://github.com/subugoe/typo3-find)
|
||||
* Alternative Zentralindizes: [K10plus-Zentral](https://verbundwiki.gbv.de/display/VZG/K10plus-Zentral), [finc Artikelindex](https://finc.info/services)
|
||||
|
||||
### Schweiz: SLSP
|
||||
|
||||
Durch [SLSP](https://slsp.ch) wird Ex Libris Alma und damit in der Regel auch das dazu gehörige Discovery-System Primo an den wissenschaftlichen Bibliotheken in der Schweiz eingeführt.
|
||||
* Durch [Swiss Library Service Platform](https://slsp.ch) wurde Ex Libris Alma und damit auch das dazu gehörige Discovery-System Primo VE an den wissenschaftlichen Bibliotheken in der Schweiz eingeführt.
|
||||
* Am Mo, 7.12.2020 ist das neue Rechercheportal [swisscovery](https://swisscovery.slsp.ch) gestartet.
|
||||
* Ergänzend zu SLSP wird vom Verein swisscollections der Sucheinstieg [swisscollections](https://swisscollections.ch) für Sammlungen angeboten. Dieses Portal wurde mit VuFind und Eigenentwicklungen der UB Basel realisiert.
|
||||
|
||||
## Zwischenfazit
|
||||
|
||||

|
||||
|
||||
# Aufgaben
|
||||
|
||||
Bis zum nächsten Termin:
|
||||
|
||||
1. Beitrag im Lerntagebuch zu dieser Lehreinheit (3000 - 4000 Zeichen)
|
||||
2. Lehrevaluation
|
||||
|
||||
@ -1,48 +1,134 @@
|
||||
# Linked Data und Testumgebung
|
||||
|
||||
1. Metadaten anreichern mit OpenRefine und Wikidata (45 Minuten)
|
||||
2. Suchanfragen mit SPARQL am Beispiel des Wikidata Query Service (45 Minuten)
|
||||
3. Testumgebung für Server-Software (30 Minuten)
|
||||
4. Empfehlenswerte Tutorials zum Selbstlernen (5 Minuten)
|
||||
* Ergebnis der Unterrichtsevaluation
|
||||
* Aktuelle Datenmodelle für Metadaten (BIBFRAME, RiC)
|
||||
* Praxisberichte
|
||||
* Suchanfragen mit SPARQL am Beispiel des Wikidata Query Service
|
||||
* Empfehlenswerte Tutorials zum Selbstlernen
|
||||
|
||||
Wir schauen uns hier in den verbleibenden zwei Lektionen das praktische Beispiel Wikidata an, dass für Bibliotheken und Archive zunehmend an Relevanz gewinnt. Ein Beispiel: Swissbib nutzt seit März 2020 die Daten aus Wikidata, siehe https://swissbib.blogspot.com/2020/03/wikidata.html.
|
||||
## Ergebnis der Unterrichtsevaluation
|
||||
|
||||
## Metadaten anreichern mit OpenRefine und Wikidata
|
||||
* Gemeinsame Sichtung der (anonymen) Auswertung
|
||||
* Rückmeldungen: 20
|
||||
* Gesamtbewertung: auf Skala 1 (unzufrieden) bis 7 (zufrieden)
|
||||
* 3x 7
|
||||
* 6x 6
|
||||
* 7x 5
|
||||
* 1x 4
|
||||
* 3x 3
|
||||
* Positive Aspekte der Lehrveranstaltung aus Sicht der Studierenden
|
||||
* Inhalt
|
||||
* Gestaltung
|
||||
* Praxisbezug
|
||||
* Materialien
|
||||
* Fachliche Kompetenz
|
||||
* Umgang mit Studierenden
|
||||
* Betreuung
|
||||
* Negative Aspekte der Lehrveranstaltung aus Sicht der Studierenden
|
||||
* Inhalt (vermutlich für Schwerpunkt Web- und Usability-Engineering?)
|
||||
* Transparenz der Lernziele
|
||||
* Forschungsbezug
|
||||
* Zeitmanagement
|
||||
* Verbesserungsmaßnahmen
|
||||
* Bei jedem Thema Bezug zu Lernzielen erläutern
|
||||
* Zusätzliche Möglichkeiten zur Überprüfung des Lernfortschritts
|
||||
* z.B. Zwischenfeedback für Lerntagebücher
|
||||
* Genauere Zielvorgabe bei Übungen
|
||||
|
||||
**Aufgabe (30 Minuten)**: Wir bearbeiten gemeinsam Teile des Tutorials "Cleaning Data with OpenRefine" von John Little (2018). Die Aufgaben unten enthalten Auszüge aus [Kapitel 5 Hands-on: Reconciliation](https://libjohn.github.io/openrefine/hands-on-reconciliation.html).
|
||||
## Aktuelle Datenmodelle für Metadaten (BIBFRAME, RiC)
|
||||
|
||||
### Aufgabe 1: Neues Projekt
|
||||
1. BIBFRAME
|
||||
2. Records in Contexts (RiC)
|
||||
|
||||
* `Create Project > Web Addresses (URLs)`
|
||||
* https://raw.githubusercontent.com/libjohn/openrefine/master/data/AA-authors-you-should-read.csv
|
||||
* `Next`
|
||||
* You many want to give your project a pretty title
|
||||
* Ja und bitte zusätzlich ein Namenskürzel/Pseudonym, damit wir uns auf dem Server nicht in die Quere kommen.
|
||||
* `Create Project`
|
||||
* Change Show: to 25 to see all 11 records.
|
||||
### BIBFRAME
|
||||
|
||||
### Aufgabe 2: Reconciliation
|
||||
* seit 2012 auf Initiative der Library of Congress als Nachfolger von MARC21 (und MODS) entwickelt, aktuell ist seit 2016 BIBFRAME 2.0
|
||||
* basiert auf *Functional Requirements for Bibliographic Records* (FRBR) sowie *Resource Description and Access* (RDA) als Regelwerk, setzt diese aber nicht vollständig um
|
||||
* folgt Linked Data Paradigmen
|
||||
* besteht aus *BIBFRAME Model* und *BIBFRAME Vocabulary*
|
||||
* Datenmodell unterscheidet zwischen *Work*, *Instance* und *Item*
|
||||
* Datenmodell definiert Entitäten *Agent*, *Subject* und *Event*
|
||||
* Vokabular definiert *Konzepte* und deren *Eigenschaften* zur Beschreibung der Entitäten des Datenmodells
|
||||
|
||||
* `authors > Reconcile > Start reconciling…`
|
||||
* Under Services, click Wikidata Reconciliation for OpenRefine (en)
|
||||
* Under Reconcile each cell to an entity of one of these types:, choose, `human`
|
||||
* Click, `Start Reconciling`
|
||||
* By clicking the approriate single checkbox in each cell of the authors column, manually select the most appropriate author for our topic. (...) Cells 2, 10 need your intervention.
|
||||
* In Cell 2, James Baldwin, select the first option which a match of “(100)”
|
||||
* In Cell 10, Click on the first name, then the second name. Do you see an African-American writer? Choose him by clicking the corresponding single check-mark
|
||||
#### BIBFRAME Model
|
||||
|
||||
### Aufgabe 3: Daten aus Wikidata ergänzen
|
||||

|
||||
|
||||
* `authors > Edit column > Add columns from reconciled values…`
|
||||
* Under Suggested Properties, click place of birth and place of death
|
||||
* OK
|
||||
Quelle: <https://www.loc.gov/bibframe/docs/bibframe2-model.html>
|
||||
|
||||
### Literatur: Reconciliation mit OpenRefine
|
||||
#### BIBFRAME Vocabulary
|
||||
|
||||
* Gemeinsame Normdatei (GND) über die API von lobid-gnd: <http://blog.lobid.org/2018/08/27/openrefine.html>
|
||||
* Tutorial zu Reconciling bei histHub: <https://histhub.ch/reconciling/>
|
||||
* Weitere Datenquellen, welche die OpenRefine Reconciliation API unterstützen: <https://github.com/OpenRefine/OpenRefine/wiki/Reconcilable-Data-Sources>
|
||||
* Und es können auch Daten manuell aus dem Web geladen und zur Anreicherung verwendet werden. Das ist aber mühseliger. Dazu ein Tutorial: <https://programminghistorian.org/en/lessons/fetch-and-parse-data-with-openrefine>
|
||||
* Ontologie umfasst Beschreibungsklassen (*Class*), die jeweils über spezifische Eigenschaften (*Property*) verfügen
|
||||
* vergleichbar mit MARC Fields und Subfields
|
||||
* Klassen/Eigenschaften sind teilweise hierarchisch strukturiert
|
||||
* z. B. "Autor" ist Spezialfall (*Subclass*) eines "Beiträgers"
|
||||
* übernimmt die Konzepte von RDA
|
||||
* siehe <https://id.loc.gov/ontologies/bibframe.html>
|
||||
|
||||
#### Was unterscheidet MARC21 und BIBFRAME? (1/2)
|
||||
|
||||
> As a bibliographic description format, the MARC format focuses on catalog records that are independently understandable. MARC aggregates information about the conceptual work and its physical carrier and uses strings for identifiers such as personal names, corporate name, subjects, etc. that have value outside the record itself.
|
||||
|
||||
Quelle: <https://www.loc.gov/bibframe/faqs/#q04>
|
||||
|
||||
#### Was unterscheidet MARC21 und BIBFRAME? (2/2)
|
||||
|
||||
> Instead of bundling everything neatly as a “record” and potentially duplicating information across multiple records, the BIBFRAME Model relies heavily on relationships between resources (Work-to-Work relationships; Work-to-Instance relationships; Work-to-Agent relationships). It manages this by using controlled identifiers for things (people, places, languages, etc).
|
||||
|
||||
Quelle: <https://www.loc.gov/bibframe/faqs/#q04>
|
||||
|
||||
#### BIBFRAME Links
|
||||
|
||||
* [BIBFRAME bei der Library of Congress](https://www.loc.gov/bibframe/)
|
||||
* [Gegenüberstellung BIBFRAME <-> MARCXML](https://id.loc.gov/tools/bibframe/comparebf-lccn/2018958785.xml)
|
||||
* [Präsentationen zu BIBFRAME auf der SWIB20](https://swib.org/swib20/programme.html)
|
||||
|
||||
### Records in Contexts (RiC)
|
||||
|
||||
* basiert auf Linked-Data-Prinzipien
|
||||
* soll neue und mehrfache Beziehungen zwischen Entitäten ermöglichen
|
||||
* Projektgruppe [ENSEMEN](https://vsa-aas.ch/arbeitsgruppen/projektgruppe-ensemen/) arbeitet an einer schweizerischen Ausprägung des neuen Standards [Records in Contexts](https://www.ica.org/en/records-contexts-german) (RiC), mit Beteiligung von Niklaus Stettler (FH Graubünden)
|
||||
|
||||
#### RiC Modell
|
||||
|
||||
* <https://www.ica.org/sites/default/files/ric-cm-02_july2021_0.pdf> (Druck S. 18 / PDF S. 23)
|
||||
|
||||
#### RiC Ontologie
|
||||
|
||||
* <https://www.ica.org/standards/RiC/ontology>
|
||||
* Beispieldateien: <https://github.com/ICA-EGAD/RiC-O/tree/master/examples/examples_v0-2>
|
||||
|
||||
#### RiC Tools
|
||||
|
||||
* Open-Source-Software [RiC-O Converter](https://github.com/ArchivesNationalesFR/rico-converter)
|
||||
* "for converting into RDF datasets conforming to RiC-O v0.1 the whole of the ANF EAD 2002 findings aids (about 28.000 XML files for now) and EAC-CPF authority records (about 15.000 XML files for now)"
|
||||
* [Artikel zur Veröffentlichung des Quellcodes](https://blog-ica.org/2020/06/13/ric-o-converter-an-example-of-practical-application-of-the-ica-records-in-contexts-standard-ica-ric/)
|
||||
* Docuteam arbeitet an Prototypen für Erschließungs- und Katalogsoftware, siehe https://ica-egad.github.io/RiC-O/projects-and-tools.html
|
||||
|
||||
#### RiC Links
|
||||
|
||||
* Einführungsartikel: David Gniffke (16.3.2020): Semantic Web und Records in Contexts (RiC). In: Archivwelt, 16/03/2020. <https://archivwelt.hypotheses.org/1982>
|
||||
* Präsentation: Florence Clavaud <https://f.hypotheses.org/wp-content/blogs.dir/2167/files/2020/02/20200128_2_RecordsInContexts_englishVersionAdded1003.pdf>
|
||||
* Arbeitsgruppe ICA EGAD: <https://www.ica.org/en/about-egad>
|
||||
* RiC Ontologie 0.2 (2019): <http://purl.org/ica/ric>
|
||||
* Access To Memory (AtoM) - Alternative zu ArchivesSpace, näher dran an RiC-Entwicklung: <https://www.accesstomemory.org>
|
||||
* Archival Linked Open Data (aLOD): <http://www.alod.ch>
|
||||
|
||||
## Praxisberichte
|
||||
|
||||
### Entwicklung eines neuen Online-Katalogs für das Deutsche Literaturarchiv Marbach
|
||||
|
||||
* Katalog (Beta): <https://www.dla-marbach.de/katalog-beta>
|
||||
* Informationen zum Projekt: <https://wdv-teamwork.dla-marbach.de/projects/info-opac-ng-hauptprojekt/wiki>
|
||||
* Unser Auftrag: Prototyp, Projektkoordination und Datenintegration
|
||||
* Geschwindigkeitsmessung mit "Network"-Funktion der Entwicklertools
|
||||
|
||||
### Datenintegration für das Portal noah.nrw
|
||||
|
||||
* Portal für Open-Access-Ressourcen in Nordrhein-Westfalen: https://noah.nrw. Besondere Funktion: Volltextsuche für Digitalisate **und** Born-Digitals.
|
||||
* Unser Auftrag: Daten von OAI-Schnittstellen abrufen, einheitlich in Format METS/MODS konvertieren und über eine OAI-Schnittstelle bereitstellen
|
||||
* Ein anderer Dienstleister erntet dann die von uns bereitgestellten OAI-Schnittstellen und kümmert sich um die Anzeige im Portal
|
||||
* Beispiel Datenquelle Biejournals: <https://github.com/opencultureconsulting/noah-biejournals>
|
||||
|
||||
## Suchanfragen mit SPARQL am Beispiel des Wikidata Query Service
|
||||
|
||||
@ -53,40 +139,35 @@ Wir schauen uns hier in den verbleibenden zwei Lektionen das praktische Beispiel
|
||||
### Tutorial
|
||||
|
||||
* Alex Stinson hat ein schönes Tutorial geschrieben, das eigentlich für Lehrende gedacht ist, aber auch individuell bearbeitet werden kann. Nach einer Einleitung, die sich an Lehrende richtet, kommt unter der Überschrift "Writing a Query" das Skript.
|
||||
* Aufgabe (30 Minuten): Bearbeiten Sie das Tutorial ab der Überschrift "Writing a Query": https://medium.com/freely-sharing-the-sum-of-all-knowledge/writing-a-wikidata-query-discovering-women-writers-from-north-africa-d020634f0f6c
|
||||
* Aufgabe (30 Minuten): Bearbeiten Sie das Tutorial ab der Überschrift "Writing a Query": <https://medium.com/freely-sharing-the-sum-of-all-knowledge/writing-a-wikidata-query-discovering-women-writers-from-north-africa-d020634f0f6c>
|
||||
|
||||
### Literatur
|
||||
|
||||
* Empfehlenswerte Tutorials zu SPARQL:
|
||||
* https://programminghistorian.org/en/lessons/intro-to-linked-data
|
||||
* https://programminghistorian.org/en/lessons/graph-databases-and-SPARQL
|
||||
* <https://programminghistorian.org/en/lessons/intro-to-linked-data>
|
||||
* <https://programminghistorian.org/en/lessons/graph-databases-and-SPARQL>
|
||||
* Beispiel, wie das Hochschularchiv der ETH-Bibliothek Wikidata nutzt:
|
||||
* How to Link Your Institution’s Collections to Wikidata? : a short manual to a semi-automatic way of using the “archives at” property (P485) https://doi.org/10.3929/ethz-b-000393724
|
||||
* How to Link Your Institution’s Collections to Wikidata? : a short manual to a semi-automatic way of using the “archives at” property (P485) <https://doi.org/10.3929/ethz-b-000393724>
|
||||
|
||||
## Testumgebung für Server-Software
|
||||
|
||||
* Während des Kurses besteht Zugriff auf die virtuellen Maschinen bei Azure Labs. Nach Ende des Kurses entfällt diese Möglichkeit.
|
||||
* Wenn Sie zukünftig einmal Server-Software testen möchten, gibt es unabhängig von der Hochschule diverse Möglichkeiten.
|
||||
|
||||
### Vergleich Cloud vs. Lokal
|
||||
|
||||
* Cloud: Root-Server (Webserver mit vollem Administrationszugriff) bei einem Webhosting-Anbieter
|
||||
* Cloud: Plattformen von Microsoft (Azure), Google (GCP), Amazon (AWS): [Kosten-Rechner](https://www.microfin.de/produkte/tools/cloud-kosten-rechner/)
|
||||
* Lokal: [VirtualBox](https://www.virtualbox.org) (Virtuelle Maschinen)
|
||||
* Lokal: [Docker Desktop](https://www.docker.com/products/docker-desktop) (Container)
|
||||
* Lokal: Booten von USB-Stick oder USB-Festplatte: [Anleitung aus BAIN HS19](https://github.com/felixlohmeier/bibliotheks-und-archivinformatik/blob/v2.0/notes_bootfaehige-usb-sticks-erstellen.md)
|
||||
|
||||
### OpenRefine auf Root-Server
|
||||
|
||||
* In diesem Kurs zeige ich Ihnen die klassische Variante "Root-Server", weil dies per Videokonferenz geht und übersichtlicher ist als die Cloud-Plattformen.
|
||||
* Wir nutzen dafür den Anbieter [Digitalocean](https://digitalocean.com), weil dieser Minutenpreise und eine einfache Benutzeroberfläche anbietet.
|
||||
* Als Anwendungsfall installieren wir OpenRefine, da wir dieses für die kommende Aufgabe gebrauchen können.
|
||||
* [Anleitung ohne Authentifizierung von mir](https://gist.github.com/felixlohmeier/0ec8b2e8241356ed52af072d9102b391)
|
||||
* [Anleitung mit Authentifizierung von Tony Hirst](https://blog.ouseful.info/2019/01/07/running-openrefine-on-digital-ocean-using-simple-auth/) (dort auch ein Link für 100 Dollar Startkredit bei Digitalocean)
|
||||
---
|
||||
|
||||
## Empfehlenswerte Tutorials zum Selbstlernen
|
||||
|
||||
* Library Carpentry: https://librarycarpentry.org/lessons/
|
||||
* Programming Historian: https://programminghistorian.org/en/lessons/
|
||||
* openHPI: https://open.hpi.de/courses
|
||||
* Datenschule: https://datenschule.de/lernmaterialien/
|
||||
* Library Carpentry: <https://librarycarpentry.org/lessons/>
|
||||
* Programming Historian: <https://programminghistorian.org/en/lessons/>
|
||||
* openHPI: <https://open.hpi.de/courses>
|
||||
* Datenschule: <https://datenschule.de/lernmaterialien/>
|
||||
|
||||
---
|
||||
|
||||
# Aufgaben
|
||||
|
||||
Bis zum Abgabetermin der Lerntagebücher:
|
||||
|
||||
1. Beitrag im Lerntagebuch zu dieser Lehreinheit (3000 - 4000 Zeichen)
|
||||
2. Abschlussartikel: “Was habe ich (nicht) gelernt?” (3000 - 4000 Zeichen)
|
||||
3. Lerntagebuch fertigstellen (ggf. ältere Beiträge korrigieren und ergänzen). Bewertungskriterien:
|
||||
* begründete kritische Auseinandersetzung mit den Lerninhalten
|
||||
* Kontextualisierung der Lerninhalte (Zusatzinformationen, Querverweise, Screenshots)
|
||||
* verständliche Darstellung in eigenen Worten
|
||||
* Vollständigkeit und Einhaltung der Form
|
||||
|
||||
148
README.md
Normal file → Executable file
@ -1,80 +1,117 @@
|
||||
# Skript zum Kurs "Bibliotheks- und Archivinformatik"
|
||||
|
||||
Dieses Skript entsteht in der Zeit von März bis Mai 2020 im Rahmen der folgenden Lehrveranstaltung:
|
||||
Dieses Skript entstand in der Zeit von September 2021 bis Januar 2022 im Rahmen der folgenden Lehrveranstaltung:
|
||||
|
||||
- Kurs "Bibliotheks- und Archivinformatik"
|
||||
- Dozent: [Felix Lohmeier](http://felixlohmeier.de)
|
||||
- Frühlingssemester 2020
|
||||
- Kurs "Bibliotheks- und Archivinformatik" (BAIN)
|
||||
- Dozenten: [Felix Lohmeier](http://felixlohmeier.de), [Sebastian Meyer](https://twitter.com/_meyse_/)
|
||||
- Herbstsemester 2021
|
||||
- Lehrauftrag an der [FH Graubünden - Studiengang Information Science](https://www.fhgr.ch/studium/bachelorangebot/wirtschaft-und-dienstleistung/information-science/)
|
||||
- Bachelor, 4. Semester, 4 ECTS
|
||||
- Bachelor, 4 ECTS
|
||||
|
||||
## Gemeinsames Dokument
|
||||
|
||||
Für Notizen und zum Austausch verwenden wir ein gemeinsames Dokument in einer [CodiMD](https://github.com/codimd/server)-Installation [bei der GWDG](https://pad.gwdg.de/). Alle, die den Link kennen, können es bearbeiten. Zur Formatierung wird [Markdown](https://www.markdownguide.org/basic-syntax/) verwendet.
|
||||
Für Notizen und zum Austausch verwenden wir ein gemeinsames Dokument in einer [HedgeDoc](https://github.com/hedgedoc/hedgedoc)-Installation [bei der GWDG](https://pad.gwdg.de/). Alle, die den Link kennen, können es bearbeiten. Zur Formatierung wird [Markdown](https://www.markdownguide.org/basic-syntax/) verwendet.
|
||||
|
||||
* [Gemeinsames Dokument](https://pad.gwdg.de/-r6PYpRjScC-w0JuI_Ovcg?both)
|
||||
* [Gemeinsames Dokument für die Gruppe ISc18tzZ (Zürich)](https://pad.gwdg.de/TI2mEmrgSbuQOP7nJsfoXg?both)
|
||||
* [Gemeinsames Dokument für die Gruppe ISc19vz (Chur)](https://pad.gwdg.de/70W-kLf9T0iW-rGHvTq7tg?both)
|
||||
|
||||
## Inhalte
|
||||
|
||||
1. [Technische Grundlagen](01_technische-grundlagen.md) (13.03.2020)
|
||||
1. [Technische Grundlagen](01_technische-grundlagen.md) (Chur: 16.09.2021, Zürich: 15.09.2021)
|
||||
- Schaubild zu Lehrinhalten
|
||||
- Einrichtung der Arbeitsumgebung (Linux)
|
||||
- Grundlagen der Unix Shell
|
||||
- Versionskontrolle mit Git
|
||||
2. [Funktion und Aufbau von Bibliothekssystemen](02_funktion-und-aufbau-von-bibliothekssystemen.md) (03.04.2020)
|
||||
- Versionskontrolle mit git
|
||||
- Blog mit GitHub Pages
|
||||
2. [Funktion und Aufbau von Bibliothekssystemen](02_funktion-und-aufbau-von-bibliothekssystemen.md) (Chur: 30.09.2021 und 07.10.2021, Zürich: 01.10.2021 und 08.10.2021)
|
||||
- Metadatenstandards in Bibliotheken (MARC21)
|
||||
- Installation und Konfiguration von Koha
|
||||
- Cloud-Konzepte am Beispiel von ALMA
|
||||
- Marktüberblick Bibliothekssysteme
|
||||
3. [Funktion und Aufbau von Archivsystemen](03_funktion-und-aufbau-von-archivsystemen.md) (24.04.2020)
|
||||
3. [Funktion und Aufbau von Archivsystemen](03_funktion-und-aufbau-von-archivsystemen.md) (Chur: 23.10.2021, Zürich: 20.10.2021)
|
||||
- Metadatenstandards in Archiven (ISAD(G) und EAD)
|
||||
- Installation und Konfiguration von ArchivesSpace
|
||||
- Marktüberblick Archivsysteme
|
||||
4. [Repository-Software für Publikationen und Forschungsdaten](04_repository-software-fuer-publikationen-und-forschungsdaten.md) (24.04.2020)
|
||||
- Installation und Konfiguration von DSpace
|
||||
4. [Repository-Software für Publikationen und Forschungsdaten](04_repository-software-fuer-publikationen-und-forschungsdaten.md) (Chur: 18.11.2021, Zürich: 19.11.2021)
|
||||
- Open Access und Open Data
|
||||
- Übungen mit DSpace
|
||||
- Marktüberblick Repository-Software
|
||||
5. [Metadaten modellieren und Schnittstellen nutzen](05_metadaten-modellieren-und-schnittstellen-nutzen.md) (05.06.2020)
|
||||
- Transformation von Metadaten mit OpenRefine
|
||||
- XSLT Crosswalks mit MarcEdit
|
||||
5. [Metadaten modellieren und Schnittstellen nutzen](05_metadaten-modellieren-und-schnittstellen-nutzen.md) (Chur: 02.12.2021 und 03.12.2021, Zürich: 02.12.2021 und 03.12.2021)
|
||||
- Austauschprotokolle für Metadaten (OAI-PMH, SRU)
|
||||
- Metadaten über OAI-PMH harvesten mit VuFindHarvest
|
||||
- XSLT Crosswalks mit MarcEdit
|
||||
- Transformation von Metadaten mit OpenRefine
|
||||
- Weitere Tools zur Metadatentransformation
|
||||
- Nutzung von JSON-APIs
|
||||
6. [Suchmaschinen und Discovery-Systeme](06_suchmaschinen-und-discovery-systeme.md) (05.06.2020)
|
||||
- Funktion von Suchmaschinen am Beispiel von Solr
|
||||
6. [Suchmaschinen und Discovery-Systeme](06_suchmaschinen-und-discovery-systeme.md) (Chur: 16.12.2021, Zürich: 17.12.2021)
|
||||
- Installation und Konfiguration von VuFind
|
||||
- Funktion von Suchmaschinen am Beispiel von Solr
|
||||
- Übung zur Datenintegration
|
||||
- Marktüberblick Discovery-Systeme
|
||||
7. [Linked Data](07_linked-data.md) (06.06.2020)
|
||||
- Testumgebung für Server-Software
|
||||
- Suchanfragen mit SPARQL am Beispiel des Wikidata Query Service
|
||||
- Zwischenfazit
|
||||
7. [Linked Data](07_linked-data.md) (Chur: 13.01.2022, Zürich: 14.01.2022)
|
||||
- Ergebnis der Unterrichtsevaluation
|
||||
- Aktuelle Datenmodelle für Metadaten (BIBFRAME, RiC)
|
||||
- Praxisberichte
|
||||
- Metadaten anreichern mit OpenRefine und Wikidata
|
||||
|
||||
Hinweise für Lehrende:
|
||||
|
||||
* [Azure Lab einrichten](azure-lab-einrichten.md)
|
||||
- Suchanfragen mit SPARQL am Beispiel des Wikidata Query Service
|
||||
- Empfehlenswerte Tutorials zum Selbstlernen
|
||||
|
||||
## Lerntagebücher
|
||||
|
||||
Als Prüfungsleistung schreiben Studierende Blogs, in denen sie von ihren Erkenntnissen berichten und sich mit den Inhalten des Seminars auseinandersetzen.
|
||||
|
||||
* [Lerntagebuch Ibrahim Aközel](https://akoezeibrahi.github.io/Blog-Bain20-Akoezel/)
|
||||
* [Lerntagebuch Alicja Bednarzewska](https://alset2103.github.io/Lerntagebuch-BAIN/)
|
||||
* [Lerntagebuch Sarah Clavadetscher](https://sarahclavadetscher.github.io/bain-lernblog/)
|
||||
* [Lerntagebuch Franziska Corradini](https://librarygirllost.github.io/bain-learning-by-doing/)
|
||||
* [Lerntagebuch Erica von Flüe](https://mimbulus89.wordpress.com/)
|
||||
* [Lerntagebuch Miklos Frank](https://bainmf.wordpress.com)
|
||||
* [Lerntagebuch Daniel Fröhli](https://ltbdf.wordpress.com)
|
||||
* [Lerntagebuch Muriel Fuhrer](https://muirgheal.gitlab.io/lerntagebuch_bain/)
|
||||
* [Lerntagebuch Martina Gerber](https://lerntagebuchbain.wordpress.com)
|
||||
* [Lerntagebuch Maximilian Grüninger](https://bain.grueninger-webdesign.ch/)
|
||||
* [Lerntagebuch Kim Hunziker](https://kimhunzikerbain.wordpress.com)
|
||||
* [Lerntagebuch Sidney Manhart](https://sidney-manhart.github.io)
|
||||
* [Lerntagebuch Samuel Martin](https://flatland.samuelnmartin.ch)
|
||||
* [Lerntagebuch Michael Mathys](https://michaelmathys.github.io/BAIN/Lerntagebuch)
|
||||
* [Lerntagebuch Mona Meier](https://bainlerntagebuchmonameier.jimdofree.com)
|
||||
* [Lerntagebuch Nadine Kramer](https://kramerbain.wixsite.com/website)
|
||||
* [Lerntagebuch Lea Reinhold](https://leaena22.github.io/BAIN-2.0/)
|
||||
* [Lerntagebuch Seraina Rutschmann](https://serainowitsch.github.io/bain/)
|
||||
* [Lerntagebuch Rachel Noemi Thommen](https://rachel-noemi-thommen.github.io/Lerntagebuch/)
|
||||
* [Lerntagebuch Matilda Z'Graggen](https://bainlernt.wordpress.com)
|
||||
* [Lerntagebuch Anya Zysset-Baschera](https://bainaz.github.io/BAINLT/)
|
||||
Gruppe ISc19vz (Chur):
|
||||
|
||||
* [Jannik Christen](https://tonytestimony.github.io/Lerntagebuch-BAIN/)
|
||||
* [Martin Heeb](https://marhee48.github.io/Lerntagebuch-BAIN/)
|
||||
* [Anna Hilgert](https://hilgeann.github.io/Lerntagebuch_BAIN/)
|
||||
* [Jacqueline Küng](https://schaglin.github.io/Mein-Lerntagebuch/)
|
||||
* [Simon Mettler](https://simon-mettler.github.io/lernblog-bain/)
|
||||
* [Barbora Plachá](https://barboraplacha.github.io/Lerntagebuch/)
|
||||
* [Jahn Sievers](https://jahnsievers.github.io/Lerntagebuch-BAIN/)
|
||||
* [Joy Walser](https://joyrw.github.io/Lerntagebuch/)
|
||||
* [Julia Zingg](https://jzingg.github.io/LerntagebuchBAIN_HS21/)
|
||||
|
||||
Gruppe ISc18tzZ (Zürich):
|
||||
|
||||
* [Jennifer Amoroso](https://saphirba.github.io/BAIN-Lerntagebuch/)
|
||||
* [Simone Behr-Schneider](https://simonebehr.github.io/LerntagebuchBAIN/)
|
||||
* [Gene Bichler](https://el-mongo-bongo.github.io/bain_lerntagebuch/)
|
||||
* [Nicolas Brauchli](https://elslothboi.github.io/Lerntagebuch/)
|
||||
* [Larissa Bucher](https://larri12.github.io/BAIN/)
|
||||
* [Christina Clerici](https://momovasco.github.io/Lerntagebuch/)
|
||||
* [Talita Fisch](https://ttly1.github.io/bain_gamora/)
|
||||
* [Sandra Freiburghaus](https://fribsle.github.io/lerntagebuch/)
|
||||
* [Joëlle Gantenbein](https://jogant.github.io/BAIN-Lerntagebuch/)
|
||||
* [Stefan Gröber](https://groebestefan.github.io/LerntagebuchBAIN21/)
|
||||
* [Lucien Haeller](http://lucienhaeller.com/lerntagebuch/)
|
||||
* [Christine Holz](https://christineholz.github.io/bain_lerntagebuch/)
|
||||
* [Marina Inglin](https://m-rina.github.io/lerntagebuch/)
|
||||
* [Nina Ingold](https://uliqwe.github.io/BAINTagebuch/)
|
||||
* [Carole Jungo](https://jungleca.github.io/Lerntagebuch_BAIN/)
|
||||
* [Melanie Käser](https://melakae.github.io/bain_lerntagebuch/)
|
||||
* [Laura Krüsi](https://sasquatchfromalaska.github.io/sasquatch_adventures/)
|
||||
* [Cynthia Kohler](https://cynkoh.github.io/BAIN21_ck/)
|
||||
* [Alexandra Köchling](https://alexandrakoechling.github.io/BAIN/)
|
||||
* [Caroline Krause](https://ckfhgr.github.io/bain-lerntagebuch/)
|
||||
* [Selina Lanz](https://slunz.github.io/Lerntagebuch-BAIN/)
|
||||
* [Joëlle Meichtry](https://schoscho77.github.io/BAIN_Sloth-O-Nator/)
|
||||
* [Adrian Menti](https://menti696.github.io/BAIN_Lerntagebuch_Adrian-Menti/)
|
||||
* [Nicole Meyer](https://kekskaempferin.github.io/Lerntagebuch/)
|
||||
* [Alan Müller](https://alanmueller.github.io/lerntagebuch/)
|
||||
* [Petra Novak](https://petra-novak.github.io/Bain21/)
|
||||
* [Lisa Oehler](https://lisaoehler.github.io/BAIN-Log/)
|
||||
* [Nino Parolari](https://nony-git.github.io/my_lerntagebuch/)
|
||||
* [Lara Pfister](https://larapfister.github.io/bain-lerntagebuch/)
|
||||
* [Sebastian Preher](https://needforsleepundersheet2.github.io/BAIN_Lerntagebuch_3.0/)
|
||||
* [Silvan Reis](https://riesling-silvan.github.io/Lerntagebuch/)
|
||||
* [Stephanie Riebe](https://striebe.github.io/BAIN_Lerntagebuch/)
|
||||
* [Sarah Roellin](https://sarahr177.github.io/BAIN-Lerntagebuch/)
|
||||
* [Livia Schmid](https://livelchen.github.io/LerntagebuchLiviaSchmid/)
|
||||
* [Antonia Stadler](https://tonydamager.github.io/BAIN/)
|
||||
* [Marion Stutz](https://stutzmarion.github.io/Lerntagebuch_BAIN/)
|
||||
* [Jessica Weidmann](https://luaynara.github.io/Lerntagebuch-BAIN-HS2021/)
|
||||
|
||||
## Modulbeschreibung
|
||||
|
||||
@ -90,9 +127,24 @@ Nach erfolgreicher Teilnahme am Modul sind die Studierenden in der Lage:
|
||||
|
||||
## Skripte der Vorjahre
|
||||
|
||||
Herbstsemester 2021:
|
||||
|
||||
* Zenodo: [10.5281/zenodo.5925567](https://doi.org/10.5281/zenodo.5925567)
|
||||
* GitHub: [v5.0](https://github.com/felixlohmeier/bibliotheks-und-archivinformatik/releases/tag/v5.0)
|
||||
|
||||
Herbstsemester 2020:
|
||||
|
||||
* Zenodo: [10.5281/zenodo.4386963](https://doi.org/10.5281/zenodo.4386963)
|
||||
* GitHub: [v4.0](https://github.com/felixlohmeier/bibliotheks-und-archivinformatik/releases/tag/v4.0)
|
||||
|
||||
Frühlingssemester 2020:
|
||||
|
||||
* Zenodo: [10.5281/zenodo.3885498](https://doi.org/10.5281/zenodo.3885498)
|
||||
* GitHub: [v3.0](https://github.com/felixlohmeier/bibliotheks-und-archivinformatik/releases/tag/v3.0)
|
||||
|
||||
Herbstsemester 2019:
|
||||
|
||||
* Zenodo: [10.5281/zenodo.3701841](https://zenodo.org/record/3701841)
|
||||
* Zenodo: [10.5281/zenodo.3701841](https://doi.org/10.5281/zenodo.3701841)
|
||||
* GitHub: [v2.0](https://github.com/felixlohmeier/bibliotheks-und-archivinformatik/releases/tag/v2.0)
|
||||
|
||||
Herbstsemester 2017:
|
||||
@ -104,4 +156,4 @@ Herbstsemester 2017:
|
||||
|
||||
Dieses Werk ist lizenziert unter einer [Creative Commons Namensnennung 4.0 International Lizenz](http://creativecommons.org/licenses/by/4.0/)
|
||||
|
||||
[](http://creativecommons.org/licenses/by/4.0/)
|
||||
[](http://creativecommons.org/licenses/by/4.0/)
|
||||
|
||||
@ -5,5 +5,4 @@
|
||||
* [4. Repository-Software für Publikationen und Forschungsdaten](04_repository-software-fuer-publikationen-und-forschungsdaten.md)
|
||||
* [5. Metadaten modellieren und Schnittstellen nutzen](05_metadaten-modellieren-und-schnittstellen-nutzen.md)
|
||||
* [6. Suchmaschinen und Discovery-Systeme](06_suchmaschinen-und-discovery-systeme.md)
|
||||
* [7. Linked Data](07_linked-data.md)
|
||||
* [Azure Lab einrichten](azure-lab-einrichten.md)
|
||||
* [7. Linked Data](07_linked-data.md)
|
||||
@ -1,66 +0,0 @@
|
||||
# Azure Lab einrichten (Hinweis für Lehrende)
|
||||
|
||||
Basiert auf: Anleitung von Microsoft zum [Einrichten eines Labs zur Schulung in Shellskripts unter Linux](https://docs.microsoft.com/de-de/azure/lab-services/classroom-labs/class-type-shell-scripting-linux)
|
||||
|
||||
## Einrichtung
|
||||
|
||||
1. Kostenloses Konto bei Microsoft Azure registrieren (170 € Startguthaben): https://azure.microsoft.com/free/
|
||||
|
||||
2. In Azure Portal einloggen und ein neues Lab-Konto einrichten: https://docs.microsoft.com/de-de/azure/lab-services/classroom-labs/tutorial-setup-lab-account
|
||||
- Wie im Tutorial beschrieben, muss der eigene Account (oder ein Gastaccount) unter **Access control (IAM)** noch als Rolle "Lab Creator" hinzugefügt werden.
|
||||
- Zusätzlich muss unter **Policies > Marketplace Images** das Image "Ubuntu Server 19.10" aktiviert werden
|
||||
|
||||
3. Unter https://labs.azure.com anmelden und ein neues Lab erstellen: https://docs.microsoft.com/de-de/azure/lab-services/classroom-labs/tutorial-setup-classroom-lab (Template erstellen dauert ca. 1 Stunde!)
|
||||
- Virtual machine (VM) size: `Small` (2 cores, 4GB RAM, $0.20 per hour)
|
||||
- Achtung: Labs sind auf 50 cores beschränkt. Das Template zählt mit, also kann man mit dieser Konfiguration 24 user ausstatten. Wenn man mehr braucht, muss man eine Supportanfrage stellen.
|
||||
- VM Image: `Ubuntu Server 19.10`
|
||||
- Enable remote desktop connecton: `Enable`
|
||||
- username: `bain`
|
||||
- password: `bainFS20`
|
||||
- quota: `40`
|
||||
|
||||
4. Mit dem Template via SSH verbinden und RDP einrichten: https://docs.microsoft.com/en-us/azure/virtual-machines/linux/use-remote-desktop
|
||||
|
||||
- ```
|
||||
sudo apt update && sudo apt upgrade
|
||||
sudo apt install xfce4 xrdp
|
||||
sudo systemctl enable xrdp
|
||||
echo xfce4-session >~/.xsession
|
||||
sudo service xrdp restart
|
||||
```
|
||||
|
||||
5. Sprache einstellen: `sudo dpkg-reconfigure locales`
|
||||
|
||||
- `de_DE.UTF-8 UTF-8` auswählen
|
||||
- Keyboard Layout muss nicht separat geändert werden
|
||||
|
||||
6. Browser (Firefox) und Texteditor (Mousepad) installieren: `sudo apt install firefox mousepad`
|
||||
|
||||
7. Dock aufräumen
|
||||
|
||||
- Ordner-Symbole links (minimieren) und rechts (Schnellzugriff) entfernen
|
||||
- Application Launcher (Lupe) entfernen
|
||||
- Launcher / Mousepad ergänzen
|
||||
|
||||
## Nutzung
|
||||
|
||||
* Die SSH und RDP-Verbindungen zu den VMs laufen auf dynamischen Ports im Bereich 49152-65535. Falls diese im Netzwerk (für die Public IP des Labs) nicht freigegeben werden können, dann muss ein Proxy verwendet werden (siehe unten: "Optional: Guacamole").
|
||||
* Nutzer\*innen benötigen ein Microsoft-Konto. Die E-Mail-Adresse der Einladung und die E-Mail-Adresse des Microsoft-Kontos müssen übereinstimmen.
|
||||
* Achtung: Wenn die Hochschule bereits mit Microsoft zusammenarbeitet, kann es sein, dass die E-Mail-Adressen der Studierenden für die Registrierung gesperrt sind. Dann müssen wohl oder übel private E-Mail-Adressen zur Einrichtung des Kontos verwendet werden.
|
||||
* Längere Ladezeiten sind einzuplanen: Das Starten und Stoppen der VMs dauert einige Minuten. Die VMs einzurichten oder zurückzusetzen dauert 1 Stunde!
|
||||
* Bei der ersten Anmeldung kann ein Passwort vergeben und jederzeit zurückgesetzt werden.
|
||||
* Die VM kann von den Lehrenden auf den Ausgangszustand (Template) zurückgesetzt werden.
|
||||
* RDP Clients für Nicht-Windows-Betriebssysteme:
|
||||
* MacOS: [Microsoft Remote Desktop 10](https://apps.apple.com/de/app/microsoft-remote-desktop-10/id1295203466)
|
||||
* Linux: [Remmina](https://remmina.org/)
|
||||
* Die öffentliche IP-Adresse des Labs bleibt konstant. Einsehbar über portal.azure.com für die Lab Creator Rolle. Die einzelnen VMs unterscheiden sich nur durch den Port (leider sind diese nur für die Nutzer\*innen einsehbar?).
|
||||
* In einem Lab kann nur eine VM bereitgestellt werden, also ggf. ein zweites Lab eröffnen. Alternativ kann das Template verändert und dann erneut veröffentlicht werden, was jedoch alle vorhandenen VMs mit dem neuen Template überschreibt.
|
||||
|
||||
## Optional: Guacamole
|
||||
|
||||
Basiert auf https://fortynorthsecurity.com/blog/apache-guacamole-how-to-install-and-configure/
|
||||
|
||||
1. Webserver mit Debian 9.x einrichten
|
||||
2. Apache Guacamole installieren mit `apt install guacamole-tomcat`
|
||||
3. Verbindungen einrichten in `/etc/guacamole/user-mapping.xml`
|
||||
4. Nutzer\*innen können sich dann unter http://localhost:8080/guacamole mit ihren Zugangsdaten anmelden.
|
||||
BIN
data/vufind-testdaten.zip
Normal file
2
docsify/docsify-pagination.min.js
vendored
2
docsify/docsify.min.js
vendored
2
docsify/search.min.js
vendored
2
docsify/zoom-image.min.js
vendored
{kind=link}
|
Before Width: | Height: | Size: 14 KiB |
{kind=link}
|
Before Width: | Height: | Size: 72 KiB |
{kind=link}
|
Before Width: | Height: | Size: 59 KiB |
{kind=link}
|
Before Width: | Height: | Size: 73 KiB |
{kind=link}
|
Before Width: | Height: | Size: 70 KiB |
{kind=link}
|
Before Width: | Height: | Size: 73 KiB |
{kind=link}
|
Before Width: | Height: | Size: 58 KiB |
{kind=link}
|
Before Width: | Height: | Size: 52 KiB |
{kind=link}
|
Before Width: | Height: | Size: 115 KiB |
{kind=link}
|
Before Width: | Height: | Size: 50 KiB |
{kind=link}
|
Before Width: | Height: | Size: 32 KiB |
{kind=link}
|
Before Width: | Height: | Size: 53 KiB |
{kind=link}
|
Before Width: | Height: | Size: 178 KiB |
{kind=link}
|
Before Width: | Height: | Size: 160 KiB |
BIN
images/cc-by-88x31.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 1.3 KiB |
BIN
images/redirects-and-pipes.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 42 KiB |
BIN
images/schaubild-lehrinhalte.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 39 KiB |
BIN
images/ubuntu-startscreen.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 219 KiB |
@ -1,9 +1,9 @@
|
||||
<!DOCTYPE html>
|
||||
<html>
|
||||
<head>
|
||||
<title>Bibliotheks- und Archivinformatik FS2020</title>
|
||||
<meta name="author" content="Felix Lohmeier">
|
||||
<meta name="description" content="Skript zum Kurs Bibliotheks- und Archivinformatik an der FH Graubünden im Frühlingssemester 2020">
|
||||
<title>Bibliotheks- und Archivinformatik (BAIN)</title>
|
||||
<meta name="author" content="Felix Lohmeier, Sebastian Meyer">
|
||||
<meta name="description" content="Skript zum Kurs Bibliotheks- und Archivinformatik (BAIN) an der FH Graubünden">
|
||||
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1">
|
||||
<meta name="viewport" content="width=device-width,initial-scale=1">
|
||||
<meta charset="UTF-8">
|
||||
@ -14,7 +14,7 @@
|
||||
<div id="app"></div>
|
||||
<script>
|
||||
window.$docsify = {
|
||||
name: "BAIN FS20",
|
||||
name: "BAIN",
|
||||
repo: "felixlohmeier/bibliotheks-und-archivinformatik",
|
||||
subMaxLevel: 2,
|
||||
search: 'auto',
|
||||
|
||||
39
metadata.yml
Normal file
@ -0,0 +1,39 @@
|
||||
name: 'Skript zum Kurs "Bibliotheks- und Archivinformatik"'
|
||||
creativeWorkStatus: "Published" # Incomplete, Draft, Published
|
||||
creator:
|
||||
- givenName: "Felix"
|
||||
familyName: "Lohmeier"
|
||||
- givenName: "Sebastian"
|
||||
familyName: "Meyer"
|
||||
description: 'Kurs "Bibliotheks- und Archivinformatik" im Studiengang Information Science der FH Graubünden'
|
||||
url: "https://bain.felixlohmeier.de"
|
||||
inLanguage: "de"
|
||||
license: "https://creativecommons.org/licenses/by/4.0/"
|
||||
learningResourceType: "Kurs"
|
||||
sourceOrganization:
|
||||
- name: "FH Graubünden"
|
||||
type: "Organization"
|
||||
about:
|
||||
- id: "https://w3id.org/kim/hochschulfaechersystematik/n06" # Bibliothekswissenschaft
|
||||
- id: "https://w3id.org/kim/hochschulfaechersystematik/n71" # Informatik
|
||||
keywords:
|
||||
- git
|
||||
- markdown
|
||||
- openrefine
|
||||
- sparql
|
||||
- solr
|
||||
- wikidata
|
||||
- xslt
|
||||
- koha
|
||||
- oai-pmh
|
||||
- library-carpentry
|
||||
- code4lib
|
||||
- dspace
|
||||
- archivesspace
|
||||
- marc21
|
||||
- vufind
|
||||
- ead
|
||||
- sru
|
||||
- open-educational-resources
|
||||
- bibliotheksinformatik
|
||||
- marcedit
|
||||